Data Mesh
10 practical tips to reduce Data Mesh's adoption roadblocks
Data Mesh is completely changing the perspective on how we look at data inside a company. Read what is Data Mesh and how it works.
Data Mesh is completely changing the perspective on how we look at data inside a company. Read what is Data Mesh and how it works.
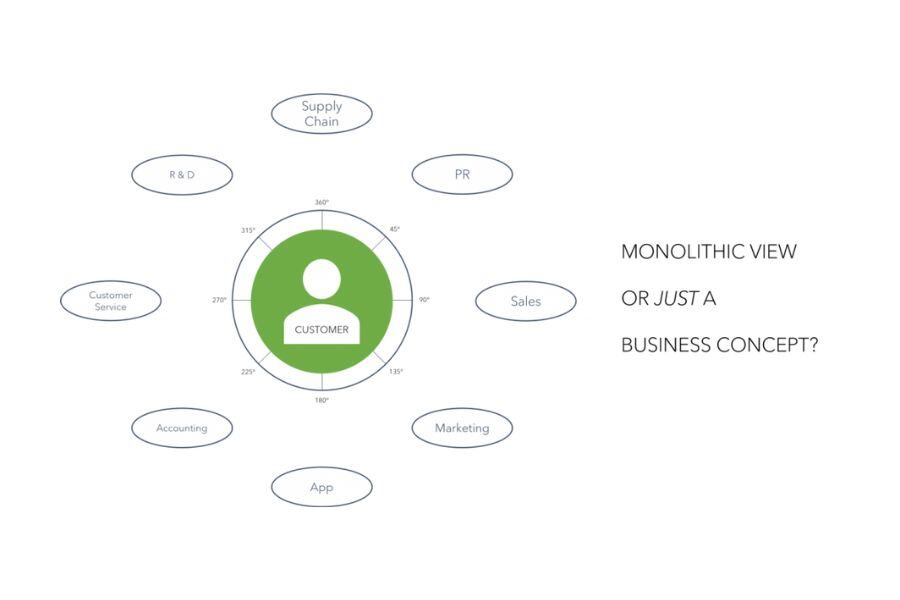
Raise a hand who saw, was asked to design, tried to implement, struggled with the “Customer 360” view/concept in the last 5+ years…
Come on, don’t be shy …
![]()
How many Customer 360 stories did you see succeeding? Me? Just … a few, let’s say. This made me ask: why? Why put so much effort into creating a monolithic 360 view thus creating a new maintenance-evolution-ownership nightmare silo? Some answers might fit here, in the context of centralized architectures, but recently a new antagonist to fight against came in town: Data Mesh.
“Oh no, another article about the Data Mesh pillars!”
No, I’m not gonna spam the web with yet-another-article about the Data Mesh principles and pillars, there’s plenty out there, like this, this, or those, and if you got here is because you might already know what we’re talking about.
The question that arises is:
How does the (so struggling or never really achieved) Customer 360 view fit into the Data Mesh paradigm?
Well, in this article I’ll try to come up with some options, coming from some real AgileLab’s customers approaching the “Data Mesh journey”.
The Data Mesh pillar I want to focus on is Domain-oriented Distributed Data decomposition and ownership.
This fascinating principle, inherited (in terms of effectiveness) from the microservices world, brings to light the necessity to keep together tech and business knowledge, within specific bounded contexts, so as to improve autonomy and velocity of data products lifecycle along with a smoother change management. Quoting Zhamak Dehghani:
Eric Evans’s book Domain-Driven Design has deeply influenced modern architectural thinking, and consequently the organizational modeling. It has influenced the microservices architecture by decomposing the systems into distributed services built around business domain capabilities. It has fundamentally changed how the teams form, so that a team can independently and autonomously own a domain capability.
Examples of well-known domains are Marketing, Sales, Accounting, Product X, or Sub-company Y (with subdomains, probably). All of these domains have probably something in common, right? And here we connect with the prologue: the customer. We all agree on the importance of this view, but eventually do we really need this to be materialized as a monolithic entity of some sort, on a centralized system?
I won’t answer this question, but I’ll make another one:
Which domain would a customer 360 view be part of?
Remember: decentralization and domain-driven design imply having clear ownership which, in the Data Mesh context, means:
If you can’t now answer the above question DON’T WORRY: you’re not alone! It just means you’re starting as well to feel the friction between the decentralized ownership model and the centralized customer 360 view.
IMHO, they are irreconcilable. Here’s why, with respect to the previous points:
OK, I’m done with the bad news Let’s start with the good ones!
As long as it remains a holistic logical/business concept. Decentralized domains should own the data related to their bounded contexts, even if referring to the customer. Domains should own a slice of the 360 view and slices should be correlated together to create valuable-on-their-own Data Products (e.g. just a join between sales and clickstreams doesn’t provide any added value, but a behavioral pattern on the website with the number of purchases per customer with specific browsing-behaviors do).
In order to achieve that, domains and - more in general - data consumers must be capable of correlating customer-related data across different domains with ease. They must be facilitated on the joining logic level, which means they should NOT be required to know the mapping between domain-specific keys, surrogate keys, and customer-related keys. I’ll try to expand this last element.
According to the Data Mesh literature, data consumers shouldn’t always copy (ingest in the first place) data in order to do something with it, since storing data means having ownership over it. As a technical step justified by volumes or other constraints for a single internal ETL step, that’s ok, but Consumer Aligned Data Products shouldn’t just pull data from another Data Product’s output port, perform a join or append another column to the original dataset, and publish at their output port an enhanced projection of some other domain’s data, for many reasons, but I won’t digress on this (again, it’s part of the Data as a Product pillar). What data consumers need is a well-documented, globally identifiable, and unique key/reference to the customer, in order to perform all the possible correlations across different domains’ data. The literature would also call them polysemes.
Note: well-documented should become a computational policy (do you remember the Federated Governance Data Mesh’s pillar?) requiring for example that, in the Data Product’s descriptor (want to contribute to our standardization proposal?), a specific set of metadata must describe where a certain field containing such key comes from, which domain generated it, what business concepts it points to. Maybe that could be done also leveraging a syntax or language that will facilitate the automated creation (thank you Self-Serve Infrastructure-as-a-Platform) of a Knowledge Graph afterward.
OK, the concepts of polysemes and the globally unique identifiable customer-related key are not new to you, and they shouldn’t, but what I want to put the lights on is how to conjugate it with the Data Mesh paradigm, especially because several architectural patterns are technically possible but just a few (one?) of them should guarantee long term scalability and compliance with the Data Mesh pillars.
The question you might have asked yourself at this point is:
Who has the ownership of issuing such a key?
The answer is probably in the good-old-friend the Master Data Management (MDM) system, where the customer’s golden record data can be generated. There’s a lot of literature (example) on that concept, also because it’s definitely not new in the industry (and that’s why a lot of companies approaching Data Mesh are struggling to understand how to make it fit in the picture since it can just be thrown away after all the effort spent on building it up).
Note: eventually, such a transactional/operational system might also lead to developing a related Source Aligned Data Product, but it should just be considered as a source of the customers’ registry information.
OK, but who should be then responsible of performing the reverse lookup, to map a domain-specific record (key) to the related customer (golden record’s) key?
We narrow down the spectrum into 3 possible approaches. To facilitate the reading of what follows, I’d like to point out a few things first:
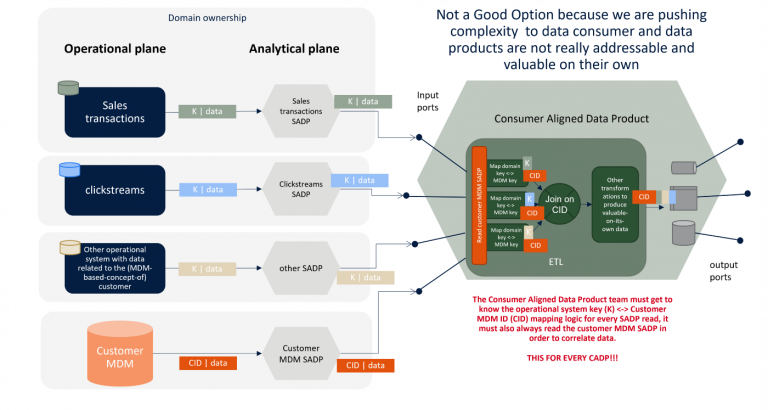
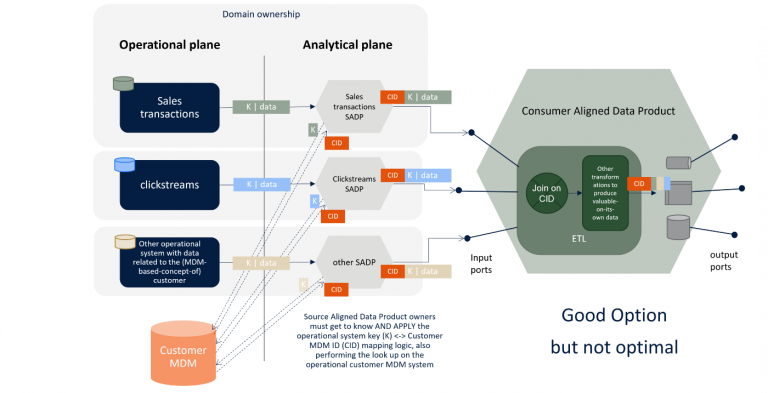
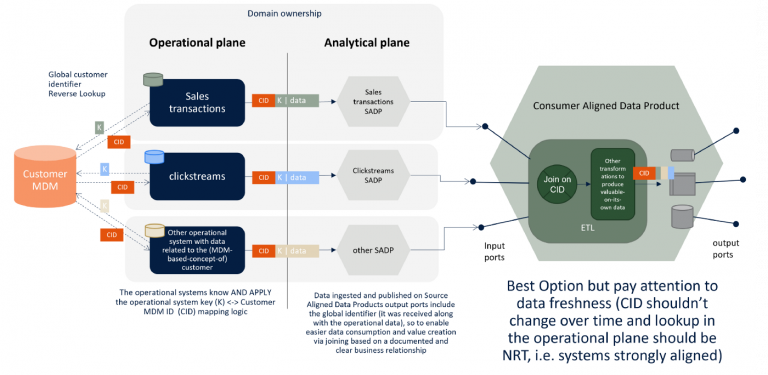
The latter approach is what could make a customer 360 view shine again! This way, domains — and in particular the operational systems’ teams- preserve the ownership of the mapping logic between the operational system’s data key and the CID, while in the analytical plane no other interactions with the operational one are required to create Source Aligned Data Products other than pulling data from the source systems, and at the Consumer Aligned Data Products sides no particular effort is spent to correlate customer-related data coming from different domains.
Disclaimer 1: approach 3 requires strong Near-Real-Time alignment between the Customer MDM system and the other operational systems since a misalignment could imply publishing data from the various domains not attached to a brand new available CID (many MDM systems operate their match-and-merge logic in batch, or many operational systems might think to update-set the CID field with batch reverse lookups quite after domain data is generated).
Disclaimer 2: a fourth approach could be possible, i.e. having microservices issuing in NRT global IDs which become master key in all the domains having customer-related data. This is usually achievable in custom implementations only.
In the Data Mesh world, domain-driven decentralized ownership over data is a must. The centralized Customer 360 monolithic approach doesn’t fit the picture, so a shift is required in order to maintain what actually matters the most: the business principle of customer-centric insights, derived from the correlation of data taken from different domains (owners) via a well documented and defined globally unique identifier, probably generated at Customer MDM level and integrated “as left as possible” into the operational systems, so to reduce the burden at the Data Mesh consumers’ side of knowing and applying the mapping logic between domain-specific key and Customer MDM key.
What has been presented has been discussed with several customers and it seemed to be the best option so far. We hope the hype around Data Mesh will bring some more options in the very next years and will keep our eyes open but, if you already put in place a different approach, I’ll be glad to know more.
If you’re interested in other articles on the Data Mesh topics, you can find them on our Knowledge Base, or you can learn more about how Witboost can get your Data Mesh implementation started quickly.
If you made it this far and you’re interested in other articles on the Data Mesh topics, sign up for our newsletter to stay tuned.
Also, get in touch if you’d like us to help with your Data Mesh journey.
Data Mesh is completely changing the perspective on how we look at data inside a company. Read what is Data Mesh and how it works.
Data Mesh is completely changing the perspective on how we look at data inside a company. Read about what Data Mesh and how it works.