A Data Platform is a Patchwork of Many Technologies
A modern data platform is a complicated mix of technologies. These technologies need to be combined for a good user experience. A data platform is built on top of a layered architecture. Each layer has a specific role:
- Data Storage Layer
- Computational Layer
- Data Governance Layer
Storage Layer
This layer contains all the platforms for storing data, like data lakes. Most of the time, this layer includes an object storage platform. In a more complex situation, this layer consists of highly specialized platforms like columnar databases, knowledge/property graphs, etc.
Computational Layer
This layer contains all the platforms offering ways to transform, query, and analyze data. Platforms like Spark, Flink, Dask, Trino, etc., are in this layer. Plenty of data digesting platforms are out there.
Data Governance Layer
This layer has to contain all the platforms needed for managing the data from different perspectives. This includes security and quality control, metadata management, etc. We could put catalogs, identity management systems, and access control engines in this layer as well.
The Complexity of Designing a Data Platform
Putting all those pieces together is a complex task. Double that when providing an excellent user experience to the platform users.
For example, users should be able to explore the available data and their meaning. They should get simple-to-use tools for data manipulation and querying. Power users should be able to access the computational platforms. These enable them to implement more advanced analytics using trained machine learning models.
Everything should be tracked and audited to support regulations like GDPR.
Designing and implementing a data platform is a complex application integration task. Unfortunately, tackling the task is too often tactical. It's based on a brute force approach to technology integration, like starting with a specific technology and then adapting the platform requirements to the technology.
The design of data platforms often lacks an adequate level of abstraction, in general. This approach would make them more resilient to technological changes, like evolving current technologies or simply adding new ones.
Another problem commonly affecting data platforms is the need for more automation. Onboarding new data, changing ownership, or making the data available to someone else is typically manual. Monitoring and rechecking data to enforce high quality both need more automation.
This general lack of automation dramatically decreases the data platform's productivity. The data platform team always needs to catch up, giving data to feed business decisions.
What could a possible strategy be to mitigate all those problems?
A Data Platform as a set of Managed Assets
The root problem is that the architect doesn’t introduce the right level of abstraction at design time. They cast the data platform architecture on a specific set of technologies. The user requirements are forcefully adapted to the target technology features.
Data engineering, as any software engineering practice, should always start from the business/user requirements. After analyzing, it is necessary to establish a coherent model that can fulfill the user's needs.
The logical model of a data platform is primarily focused on how the data is collected and managed. It mainly describes the data containers. So, a data platform is a collection of managed assets used collectively for storing and managing data.
A list of possible managed assets could be:
- Data Collection: a generic container of data; it could be a filesystem or an object storage folder containing files. It could also be a RDBMS table.
- Data Product: The managed asset is a data product if our platform follows the data mesh socio-architectural pattern.
- Data Transformation Pipeline: a sequence of data transformation steps.
All these assets are defined without any specific technology. The assets describe the logical model using metadata. This could mean a list of user defined properties that fulfill the needs.
The Data Platform Catalog
All the managed assets and their definitions must be stored in a flexible catalog. This catalog should support a simple design process:
- Gathering user requirements.
- Analyzing and defining a logical model.
- Defining the logical assets inside the catalog.
- Ensuring the compilation/transformation rules define the corresponding physical assets inside the catalog.
- Defining the provisioning tasks that deploy the physical assets on the target technologies.
The illustration below shows the process and the role these knowledge graphs play.
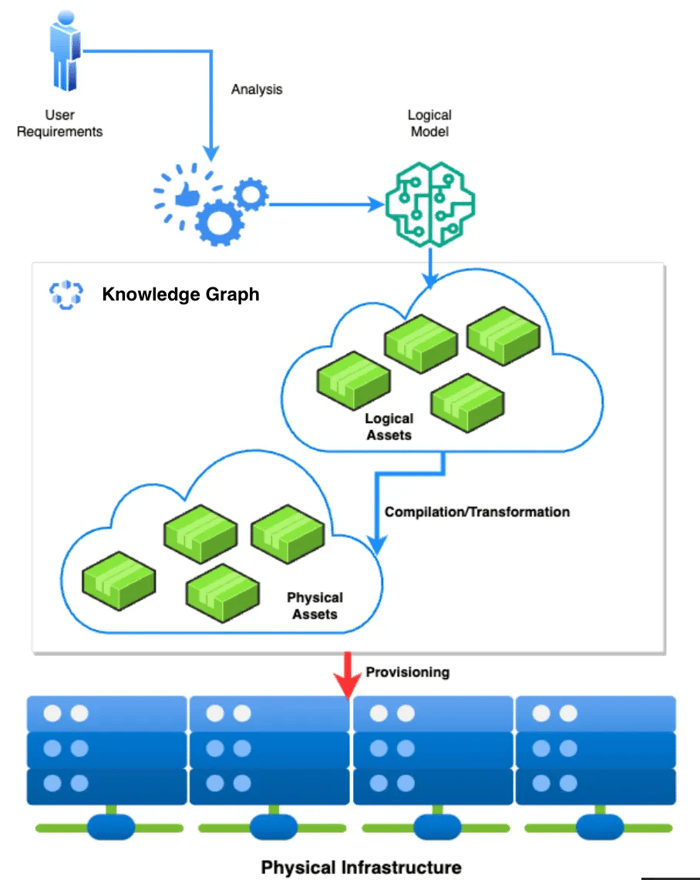
Knowledge graphs supporting this approach should be able to:
- Allow users to define types together with a schema.
- Mark a user-defined type with “traits” to describe its kind and behavior.
- Strict separation between the shape/form of a type and the relationships among each other. In a data platform, the managed assets are mainly characterized by their relationships.
Data Platform Shaper
The Data Platform Shaper is a highly configurable metadata knowledge graph. It supports the design of complex data platforms with a technology agnostic approach.
Our first implementation uses a knowledge graph, based on RDF technologies, either graphdb or virtuoso. In general, any knowledge graph supporting rdf4j can be used.
We designed our catalog system based on an ontology structured into four layers (L0, L1, L2, L3):
- L0 provides the mechanism for creating user-defined types.
- All the types are defined in L2, which is a container for all the possible user-defined types.
- Each user-defined type is associated with a name and a schema:
- A schema is a list of pair names/types.
- A type can also be formatted like a list, structure, or option (optional attribute). It supports an arbitrary level of nesting.
- L1 describes all the traits corresponding to the asset kinds.
- A trait can be used to represent the behavior of a user-defined type.
- L1 defines all the possible structural relationships among traits.
- These will be inherited by all the instances automatically, implementing those traits.
- L3 contains all the user-defined type instances.
The prototype is available with an Apache 2 open-source license on GitHub.
It’s a micro-service exposing REST APIs. These create traits, relationships among them, user-defined types with their schema, and user-defined types instances.
The README file provides examples for getting the hang of this system. The documentation provides additional examples and describes the internal behavior and APIs.
Let's see how this works through an example.
L0: The Basic Machinery
The L0 ontology layer provides the mechanisms for defining a user-defined type together with a schema:
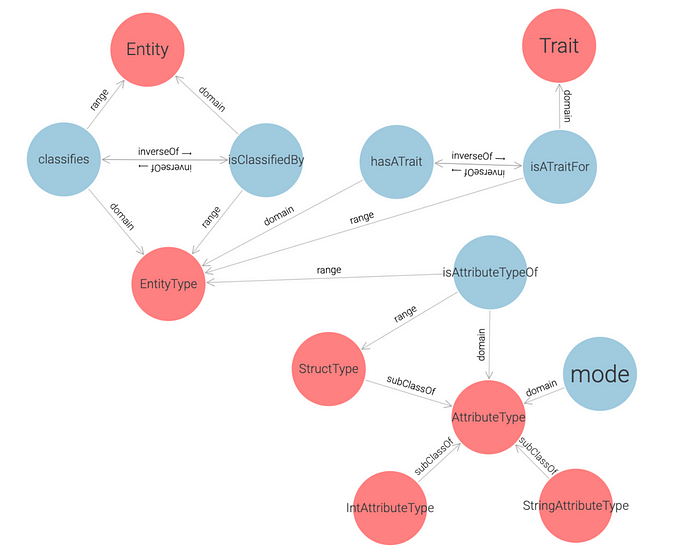
A user-defined type is an instance of EntityType. An EntityType can be associated with one or more Traits. An EntityType associates with AttributeType.
An AttributeType can be StringType, IntType, LongType, etc. We support all the basic types, including date and timestamp.
A particular attribute type is StructType. It can contain other attribute types, which is the mechanism that allows arbitrary nesting levels.
The Mode entity is a listing: Nullable, Repeated, Required. The meaning is obvious. An attribute can be optional, repeated (a list of values), or mandatory.
Using the L0 entities and their relationships, you can define complex nested schemas. These further associate with the user-defined types.
L1: Traits and Relationships
This layer contains a predefined list of possible relationships among Traits. Currently, we provide the hasPart relationship, for example, in this picture:
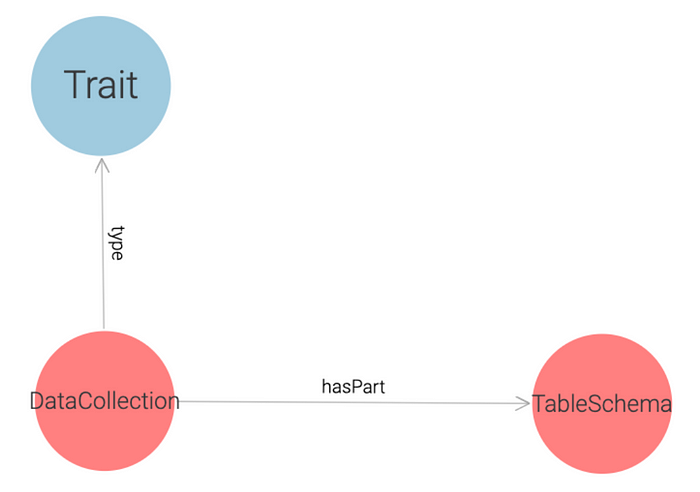
The trait DataCollection links to the TableSchema trait through the hasPart relationship.
L2: User-defined Types
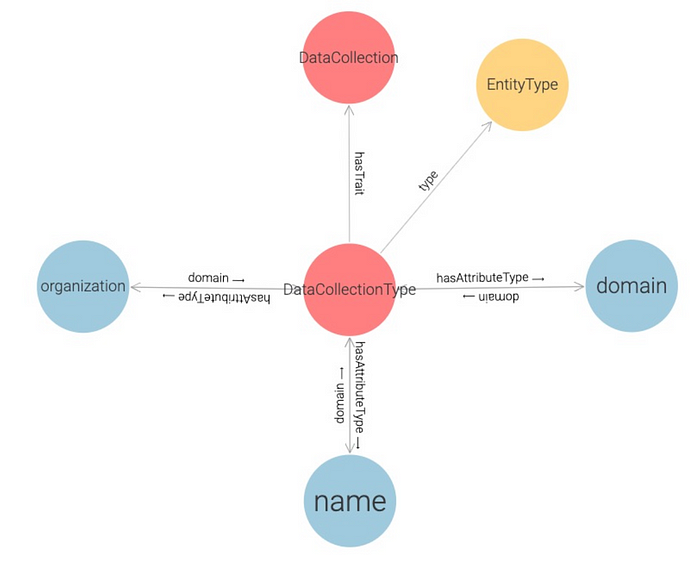
Suppose we describe a managed asset called DataCollectionType, which represents a generic data collection. To mark this user-defined type as a data collection, we must associate it with the trait DataCollection.
We build a user-defined type by assembling a name, a schema, and a list of traits. We provide a REST API that accepts a YAML document representing a user-defined type definition:
name: DataCollectionType
traits:
- DataCollection
schema:
- name: name
typeName: String
mode: Required
- name: organization
typeName: String
mode: Required
- name: domain
typeName: String
mode: Required
This definition generates the following graph:
Let’s see a more complex example:
name: TableSchemaType
traits:
- TableSchema
schema:
- name: tableName
typeName: String
mode: Required
- name: columns
typeName: Struct
mode: Repeated
attributeTypes:
- name: columnName
typeName: String
mode: Required
- name: columnType
typeName: String
mode: Required
This example shows a repeated structure and columns, containing two attributes. This definition produces the following graph:
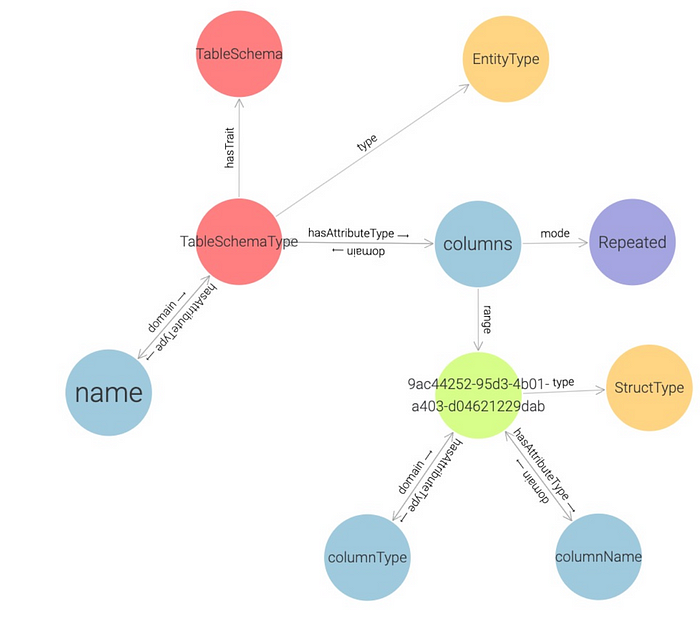
L3: User-defined Types Instances
Now that we have the user-defined types described, we can create instances of them. For example, the system provides a REST API accepting a YAML document for instance creation.
Let’s create an instance for the DataCollectionType user-defined type:
entityTypeName: DataCollectionType
values:
name: Person
domain: Registrations
organization: HR
And the corresponding graph:
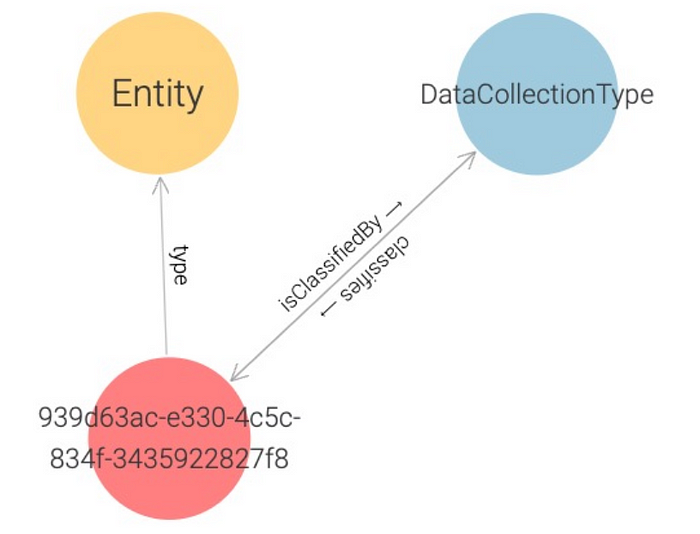
Now, let’s create an instance of TableSchemaType user-defined type:
entityTypeName: TableSchemaType
values:
name: Person
columns:
- columnName: firstName
columnType: String
- columnName: familyName
columnType: String
- columnName: age
columnType: Int
And the corresponding graph:
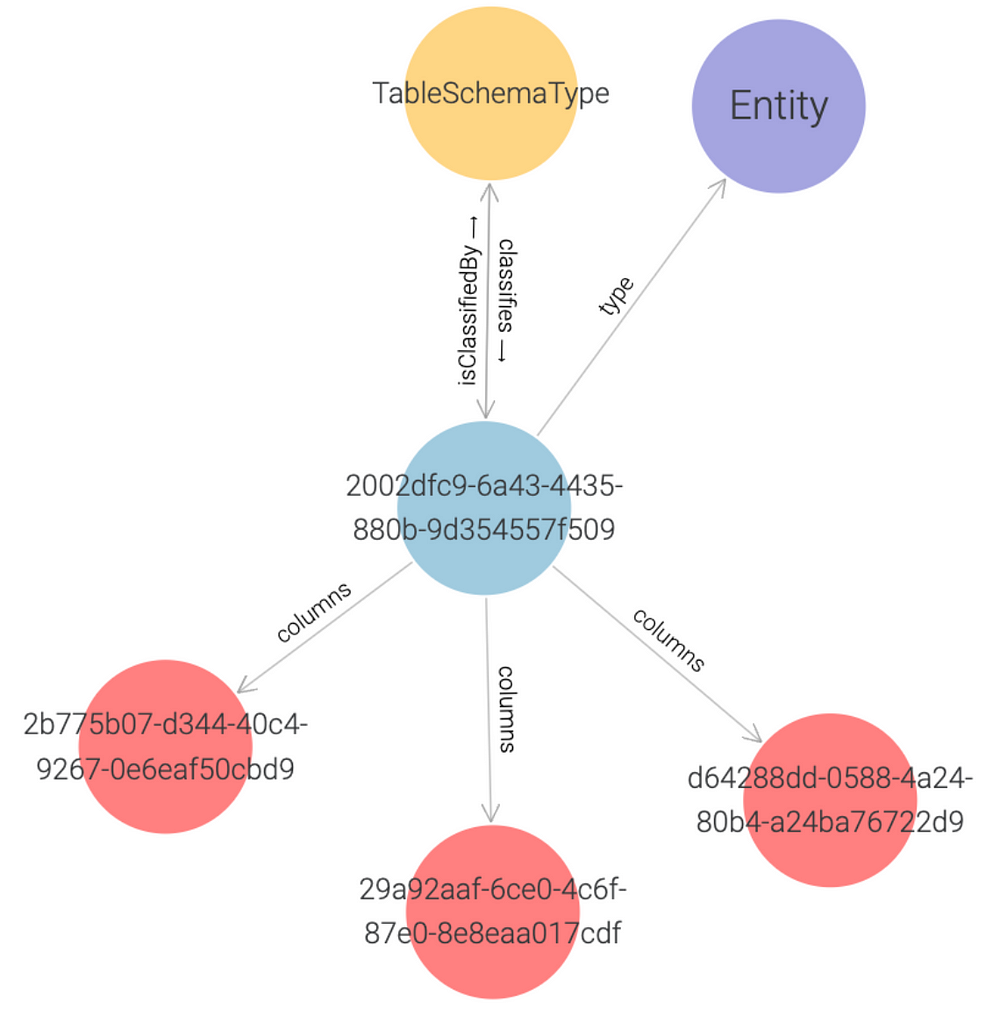
L3: Linking instances
An interesting property of the system is that all the instances of the user-defined types with the same traits can link, if a relationship links two traits.
This property is mandatory. For example, two instances can be linked through a relationship, R, only if the two types, T1 and T2, of the two instances are associated with two traits, TR1 and TR, linked by R.
In our example, DataCollection links with TableSchema through the hasPart relationship. Thus, any instance of types associated with those traits links with the same relationship.
This graph shows the link between an instance of DataCollectionType and an instance of TableSchemaType:
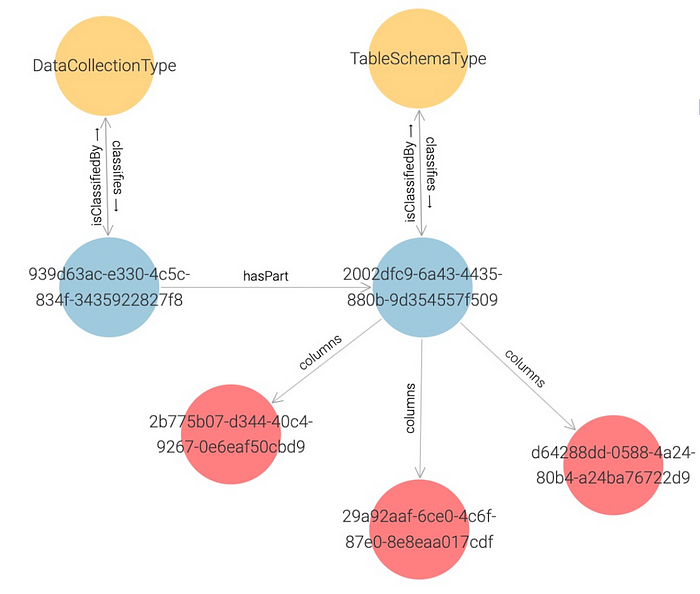
Next Steps
We are considering adding a validation mechanism to the system. We want the user to define constraints on the possible values for the instance attributes. We are considering different possibilities, such as integration with CUE or SHACL.
Conclusions
The Data Platform Shaper is a flexible catalog and is still a work in progress. It aims to contain all the information around managed assets that compose a modern data platform.
Our vision is to extend it with new ideas. These will support the process of designing and implementing a modern data platform. The starting point is a pure and technologically agnostic model that moves toward the physical model. This is where the logical data assets map to their physical counterparts.
This article was created from a published research paper. It was presented at the 2023 IEEE International Conference on Big Data.
Credits
This project is the result of a collaborative effort of an amazing team:
| Name |
Affiliation |
| Diego Reforgiato Recupero |
Department of Math and Computer Science, University of Cagliari (Italy) |
| Francesco Osborne |
KMi, The Open University (UK) and University of Milano-Bicocca (Italy) |
| Andrea Giovanni Nuzzolese |
Institute of Cognitive Sciences and Technologies National Council of Research (Italy) |
| Simone Pusceddu |
Department of Math and Computer Science, University of Cagliari (Italy) |
| David Greco |
Big Data Laboraty, Agile Lab (Italy) |
| Nicolò Bidotti |
Big Data Laboraty, Agile Lab (Italy) |
| Paolo Platter |
Big Data Laboraty, Agile Lab (Italy) |