There is a sentence we keep hearing from data leaders across industries, and it captures something fundamental about how governance is perceived in most organisations. A customer in the financial services space once told us: "Governance is important, but delivery comes first." He was being honest, because this is typically how things happen “I need to deploy today because I have a deadline, then tomorrow I’ll fix masking, metadata and quality”. This is a change management failure.
The problem isn’t that governance isn’t being valued by people. Every CDO we've spoken to in the last two years understands why governance matters — for compliance, for data quality, for AI readiness, for trust.
The problem is that governance, as it's typically implemented, operates as a parallel process to delivery. It lives in different tools, runs on different timelines, and depends on different people. So when delivery pressure increases, governance is the activity that gets deferred, because it's not embedded in the flow of work. It sits alongside it.
In this article, we propose a different framing. Governance doesn't have to be something you do in addition to building data products. It can be something that happens as a consequence of building data products — if the architecture is designed correctly.
In a previous article we described why disconnected change management is the structural root cause behind metadata drift, stale catalogs, and broken data contracts. Here we want to go a step further: not just fixing the drift, but turning governance into something that actively accelerates delivery instead of slowing it down.
The argument is rooted into four design principles. None of them is particularly radical on its own. What's powerful is the compounding effect when all four operate together. They create a system where compliance becomes the path of least resistance, and the organisation converges toward quality without anyone needing to police it.
Principle 1 – Computational Policies
The most common governance pattern we encounter in large organisations is the governance committee: a group of people who review data products, metadata definitions, or architectural decisions before they can proceed to the next stage.
At small scale a committee of five people can reasonably review everything. But committees are fundamentally a linear process applied to a problem that grows combinatorially — more data products, more domains, more policies, more stakeholders — and at some point the committee becomes the single biggest bottleneck in the entire data organisation.
The alternative is to express governance rules as computational policies — rules that a machine can evaluate automatically, without human intervention, every time a data product is deployed.
- "All data contract fields must have a business description" - becomes an automated check in the delivery pipeline.
- "DORA classification must be declared in the descriptor" - becomes a gate that rejects the deployment if the classification is absent.
- "Fields with names suggesting personal data should carry a PII tag" - becomes an LLM-based policy that reads the schema, infers sensitivity, and flags the gaps.
The important nuance here is that computational doesn't mean rigid. One of the mistakes we've made in the past (and it taught us a lot) was introducing strict policies too early in the adoption journey, which created real antagonism between the platform team and the domain teams.
The platform team became “the team that blocks my deployments,” which is the fastest way to kill adoption. What works much better is a graduated model: new policies start as warnings, they surface violations but don’t block deployments, and after a grace period, between 3-6 months, they become hard gates. By the time a policy becomes blocking, people already know about it, understand it, and have adapted their workflow.
You can also express compliance as a maturity score rather than a binary pass/fail, which turns governance from a gatekeeper into a compass: your data product has a score of 72%, here's what you need to improve to reach 85%.
The fundamental shift is moving governance from a synchronisation problem to an automation problem, which computers and particularly AI is very good at solving.
Principle 2 – Shift Left Data Governance
Most governance is applied after the fact. The team builds the data product, deploys it, and then discovers (often through a rejection) that some policy wasn't satisfied. Maybe the metadata is incomplete. Maybe the data classification is missing. Maybe the data quality rules don't cover a required dimension.
The result is rework: go back, fix it, re-deploy, wait for another review cycle. This back-and-forth is expensive, frustrating, and entirely avoidable.
The concept of shift-left comes from software development, where the industry learned that catching bugs or debt during development is dramatically cheaper than catching them in production.
The same logic applies to data governance, but with an important twist: shift-left in governance is not just about running checks earlier — it's about making the rules visible and comprehensible from the very first moment someone starts working on a data product.
Imagine starting a new data product and being able to see, immediately, every policy that will be evaluated at deployment. You know what metadata fields are mandatory. You know what data classification is required. You know what data quality assertions need to exist. You know the naming conventions, the documentation requirements, the SLA expectations. This isn't a wiki page somewhere — it's a live view that reflects the current state of the organisation's governance expectations, and it updates as new policies are introduced.
This has a profound effect on how people work, for three reasons.
- It eliminates surprises: nobody gets blocked at the gate by a rule they didn't know existed.
- It creates a shared understanding of what "done" actually means across the organisation, which is far more powerful than any governance handbook.
- It changes behaviour at the source: when people know what's expected before they start, they build it right the first time instead of building something and then retrofitting compliance.
The deeper insight is that the lifecycle itself becomes a form of guidance. When each phase of the data product lifecycle communicates clearly what needs to happen, what will be checked, and what the criteria are for moving forward, teams acquire genuine autonomy.
They don't need to ask permission or wait for a committee, because the system has already made the expectations explicit. Autonomy and governance stop being opposing forces — they become complementary aspects of the same process.
Principle 3 – Unified Change Management
We explored this topic in depth in a previous article, so we won't repeat the full analysis here. But the core argument is essential to the governance-as-accelerator thesis, so let us state it concisely.
The structural reason governance drifts is that metadata, documentation, data contracts, quality rules, and code are managed through separate change management processes, in separate tools, by separate people, at separate times.
No amount of discipline or tooling can overcome this architectural fragmentation. If the processes are disconnected, the artifacts will diverge. The solution is to unify them: every artifact that constitutes a data product (i.e. code, metadata, infrastructure, documentation, contracts, quality rules) should be authored, versioned, validated, and deployed as a single atomic unit of work, through the same pipeline, at the same time.

What we want to add here, beyond the change management argument, is the data governance implication. When everything moves through one pipeline, data governance has exactly one place to enforce compliance.
The place where this unification of change management could happen is Git – managing everything as code. The computational policies from Principle 1 evaluate all artifacts in a single pass. The shift-left visibility from Principle 2 applies to every dimension simultaneously (i.e. metadata completeness, documentation quality, contract validity, security classification) because they're all part of the same change.
Unified change management is the architectural foundation that makes the other principles practical. Without it, each principle operates in isolation and the benefits are incremental. With it, they compound.
Principle 4 – Generative Compliance
This is the principle with the highest leverage, and the one that makes the entire system self-reinforcing.
If you are using AI in building data products — generating code, scaffolding metadata, drafting documentation, creating data contract templates — then you have the opportunity to close a loop that changes the economics of governance fundamentally.
Your computational policies already define, in machine-readable terms, what a compliant data product looks like: which fields are mandatory, what naming conventions apply, what quality rules are expected, how sensitive data should be classified. If you feed these policy definitions into the AI agent that generates data products, the agent produces artifacts that are compliant by default because the generation process was informed by the rules from the start.
And this goes further. When the policy engine does flag a violation — perhaps a new policy was introduced, or the agent missed a subtlety — the violation result feeds back into the agent's context. The next time it generates a similar artifact, it already knows about that rule. Over time, the first-pass compliance rate increases organically. The governance team defines rules, and the machine absorbs them into its generation process — automatically, without anyone needing to retrain the model or update a template.
For non-technical users, this is particularly powerful. They interact through a form or a natural language interface, never seeing the underlying code or the governance policies. Behind the scenes, the AI agent produces all the necessary artifacts — infrastructure definitions, metadata, data contracts, documentation — already compliant with whatever the organisation requires.
The user doesn't need to know about PII tagging policies or DORA classification requirements. The system handles it. Governance becomes invisible not because it's been removed, but because it's been absorbed into the generation process.
Think of this as the shift from "check at the gate" to "built into the blueprint." When governance rules instruct the AI that generates the artifacts, compliance is no longer a verification step — it's a property of the output.
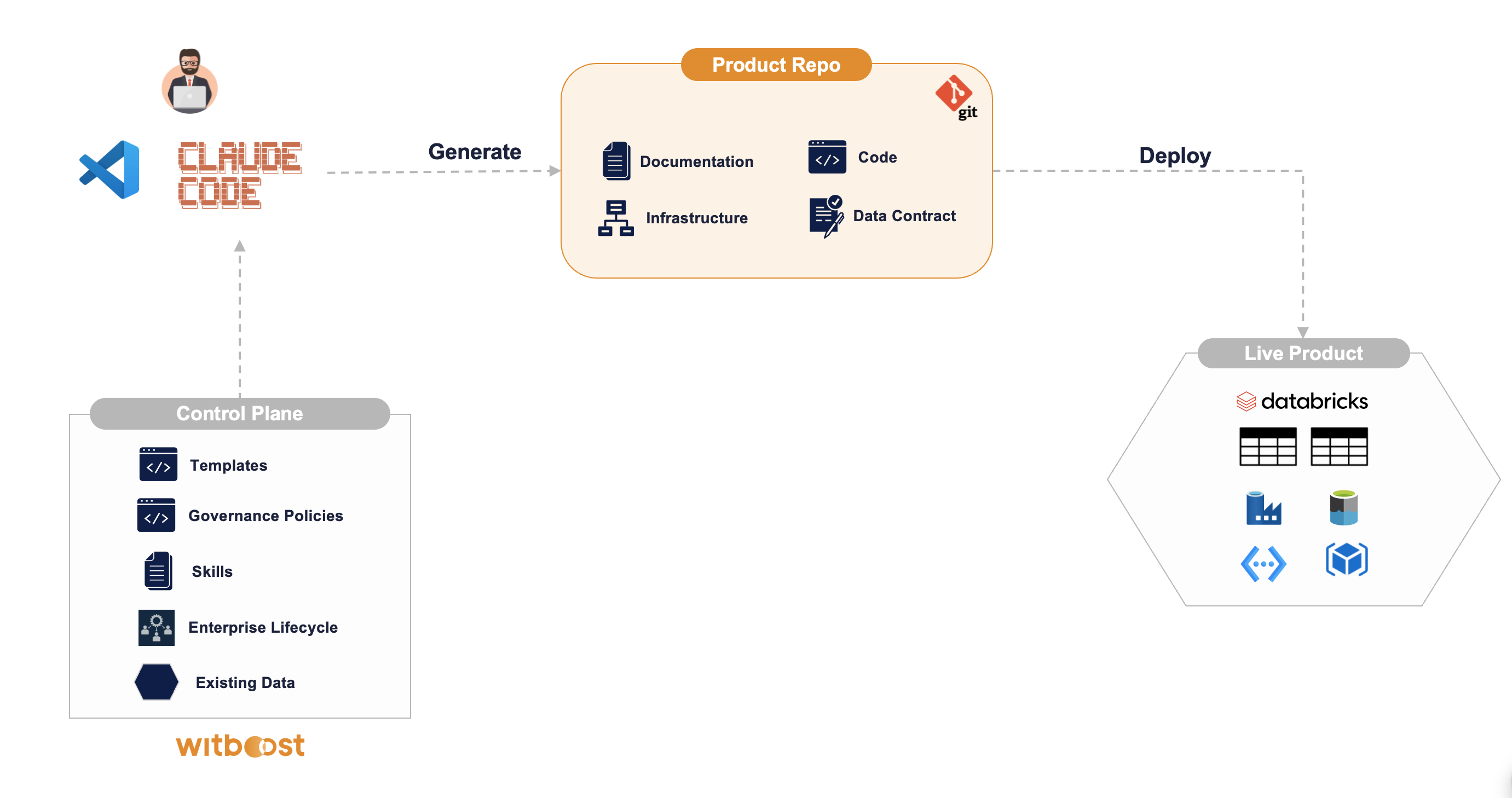
The Data Governance Flywheel
These four principles are not independent improvements. They form a system, and the value of the system is in the compounding effect.
-
Each computational policy you add makes the delivery pipeline more intelligent.
-
Each policy that is visible from day one reduces the rework caused by late-stage rejections.
-
Each agent that monitors production catches drift before it reaches consumers. Each artifact managed through a unified pipeline is one fewer source of inconsistency.
-
Each governance rule that feeds into the generative AI makes the next data product more compliant from birth.
Over time, a pattern emerges: governance violations decrease because the system absorbs the rules into its operating logic. The governance team focuses on defining what "good" looks while the platform ensures that "good" is the default outcome. New teams onboarding to the platform don't face a wall of governance documentation they need to internalise before they can start working. They start building, and the platform guides them toward compliance through the lifecycle, the policies, and the AI assistance.
The underlying principle is that governance converges by design when the architecture makes compliance the path of least resistance. Not because there is a governance committee enforcing alignment. Not because people are diligent and disciplined. Because the system is designed so that doing the right thing is easier than doing the wrong thing.