The real reason data catalogs, documentation, governance rules, data quality definitions, and data contracts fall out of sync is not weak tooling but disconnected change management. When these artifacts are updated separately from the software lifecycle, drift becomes inevitable. The fix is to manage every data change as one atomic, versioned release through a unified Control Plane that combines engineering delivery with governance, approvals, and compliance checks.

Your data catalog is out of date. Your information model doesn’t reflect what’s actually running in production. Your Confluence documentation was last accurate three sprints ago. Your data contracts exist, but the SLAs they describe belong to a version of the pipeline that no longer exists.
You know this. Everyone knows this. And the industry’s response has been predictable: blame the tool. The catalog isn’t good enough. The documentation platform lacks the right integrations. The data contract standard isn’t mature yet. We need a better registry.
Here is a different thesis: the tools are not the problem. The change management cycle is the problem.
At the Gartner Data & AI Summit 2026, composable data management, data product operationalisation, and platform engineering for data as the proper foundations for AI dominated the conversation.
Every vendor on the exhibition floor promised better metadata, better context, better governance for AI. But not a single conversation we had — not one — addressed the structural reason why all of these systems drift out of sync within weeks of going live.
That reason is simple, and it is the same reason across every organisation we work with: the change management process for metadata, governance, documentation, and data quality is structurally disconnected from the change management process for software. And until you fix that disconnect, no tool will save you.
The Symptom Everyone Recognises
Let’s catalogue the failures. They are universal:
- Data catalog: populated during a “metadata sprint” or a data governance programme kickoff. Within three months, 40% of entries are stale. Within six months, teams stop trusting it. Within a year, it becomes the system that “we should really update.”
- Information model repository: documented by architects, maintained by nobody. The logical model says the customer entity has 12 attributes. The physical schema has 18. Nobody can tell you when or why the divergence happened.
- Documentation (Confluence, wikis): written once with good intentions. Never updated because updating documentation is not part of the development workflow — it is a separate, voluntary activity that competes with sprint commitments.
- Data quality rules: defined in a governance tool, disconnected from the pipeline that produces the data. The rules reference columns that were renamed two releases ago.
- Data contracts: published in a registry, version 1.2. The actual output port is on version 1.5. The breaking change was never formally declared because nobody updated the contract when the schema changed.
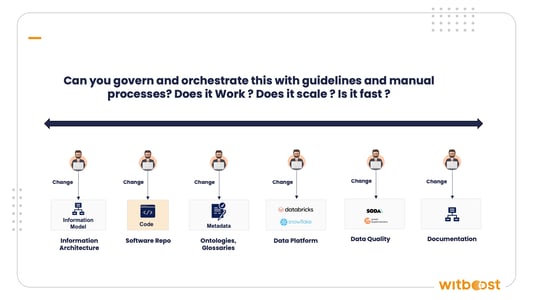
Here is what matters: these failures persist even when organisations adopt data products and data contracts. Data products and data contracts are excellent practices. They introduce ownership, accountability, and interface-level thinking. But they are still practices — they rely on principles and intent. If the underlying change management process doesn’t change, the same drift occurs, just with better vocabulary.
You can adopt a standard descriptor format. You can document data products in a beautiful catalog. You can write data contracts with full SLA definitions. But if the lifecycle of those artifacts doesn’t move in lockstep with the lifecycle of the software that produces the data, you will always be out of sync.
The Root Cause Nobody Talks About
The fundamental problem is this: metadata, documentation, governance rules, data quality definitions, and data contracts are managed through a change management cycle that is not synchronised with the software change management cycle.
Software changes are versioned, reviewed, tested, and deployed through CI/CD. Metadata changes happen in a catalog UI, days or weeks later, by a different person, through a different process. Governance policies are updated in a PDF after a committee meeting. Documentation is “refreshed” during a quarterly review. Data quality rules are updated when someone notices a failure — which is to say, after the damage is done.
Consider an analogy from the physical world. When a company launches a physical product, everything ships together. The packaging, the marketing materials, the instruction manual, the regulatory certifications, the shelf placement, the pricing; all of it is coordinated to arrive at the same moment. Nobody ships the product to retail shelves and then says, “We’ll update the packaging in a few weeks when the marketing team has bandwidth.”
This seems obvious. Yet in data management, we do exactly this. We deploy a pipeline change — the “product” — and then expect that the metadata, the documentation, the governance classification, the data quality rules, and the data contract will all be updated separately, by different people, through different systems, at different times.
The result is inevitable: perpetual inconsistency. Not because people are negligent, but because the system architecture makes consistency structurally impossible. You cannot maintain coherence across six different tools with six different change management processes and expect them to converge.
The Atomic Release Principle
Here is the framework that resolves this: every change to a data product must be released atomically.
Consider what happens when you need to add a single column to a data contract. This is one of the most common operations in data management. It requires:
- Modifying the logical model (if one exists)
- Changing the physical schema of the target table
- Writing a migration script
- Modifying the ETL/pipeline that populates that column
- Adding a business description and associating business terms
- Classifying the new data element (PII? Sensitive?)
- Defining data quality rules for the new field
- Adding data protection rules (masking, tokenisation)
- Reviewing and updating sharing agreements and access policies
Nine changes. In most organisations, these happen in at least four different systems (Git, data catalog, quality tool, documentation platform), by at least three different roles (engineer, data steward, governance officer), through at least three different processes (PR workflow, manual catalog update, governance committee review).
The Atomic Release Principle states: all changes that constitute a single logical modification to a data product must be authored, validated, and deployed as a single unit of work — in the same commit, through the same pipeline, at the same time.
If you cannot make all these changes in a single place and release them atomically and automatically, you will always have consistency problems. This is not a governance problem. It is not a people problem. It is a change management architecture problem.
The Control Plane Model
The Atomic Release Principle requires a specific kind of system to enforce it: a control plane that is rooted in software change management but extends to cover the full enterprise lifecycle.
This is not just “deploy to production.” Enterprise reality is more complex than that. A change to a data product must:
- Progress through environments (dev → staging → production)
- Receive approvals from relevant stakeholders (architectural board, data governance, security officer, DPO)
- Satisfy automated governance policies (metadata completeness, compliance classification, quality thresholds)
- Execute infrastructure provisioning and data pipeline deployment
- Update all dependent systems (catalog, marketplace, lineage graphs)
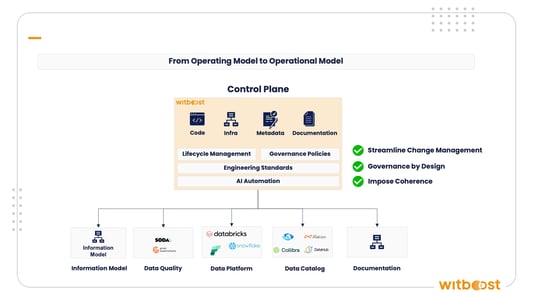
The control plane must harmonise two things that are traditionally managed in complete isolation:
- The Git-based engineering lifecycle — where code, configuration, metadata descriptors, data contracts, quality rules, and documentation all live as versioned artifacts
- The enterprise governance lifecycle — where approvals, environment promotions, compliance checks, and stakeholder sign-offs happen
When these are disconnected — when the engineering team deploys through Git/CI/CD but governance happens through email and committee meetings — you get the worst of both worlds: engineering velocity without governance alignment, or governance compliance without engineering agility.
The control plane unifies them. It ensures that:
- Nothing reaches production without satisfying both engineering quality gates AND governance policies
- Every artifact moves together — code, metadata, contracts, documentation, quality rules — as a single versioned unit
- Governance checks are computational (automated, evaluated at deploy time) rather than procedural (meetings, manual reviews, email chains)
- The enterprise lifecycle (approvals, environment progression) is orchestrated within the same system that manages the engineering lifecycle
The Operating Model That Scales
At the Gartner Data & AI Summit, one theme was inescapable: organisations are struggling to operationalise data products at scale. They have the strategy. They have the tooling. They have the teams. What they don’t have is an operating model that makes quality convergent by design.
The combination of these four principles produces that operating model:
|
Principle
|
What It Solves
|
|
Everything as Code
|
Metadata, contracts, policies, docs — all versioned in Git. Single source of truth.
|
|
Atomic Release
|
All artifacts move together. No drift between systems. Consistency by construction.
|
|
Computational Governance
|
Policies evaluated automatically at deploy time. No manual gates. No committees as bottlenecks.
|
|
Enterprise Lifecycle Integration
|
Your Data Catalog and Data Platform Are Always Out of Sync
|
When these four principles operate together, something fundamental changes: quality converges by design, not by effort.

In the traditional model, quality is maintained by people who manually check, review, update, and synchronise across systems. This is heroic work, and it never scales. The more data products you have, the more the entropy grows. Eventually, the organisation accepts that “the catalog is never quite up to date” and moves on — paying the cost in duplicated data, inconsistent semantics, compliance gaps, and failed AI initiatives that cannot trust the metadata they depend on.
In the unified change management model, quality converges because the system architecture makes inconsistency impossible. You cannot deploy a pipeline change without the metadata. You cannot release a new column without the business description. You cannot promote to production without the governance classification. The control plane enforces atomicity, and atomicity produces consistency without requiring human vigilance.
This is the operating model that allows organisations to accelerate without compromising quality. Not because governance is relaxed — but because governance is embedded in the same workflow that engineers already use. The path of least resistance becomes the compliant path. Teams move fast because they never have to context-switch between “building” and “governing” — it is the same activity.
The data industry has spent a decade building better catalogs, better contract formats, and better documentation platforms. The tools are not the problem. They never were.
The problem is that we manage the lifecycle of data artifacts through a fundamentally different process than the lifecycle of the software that produces them. Until these two lifecycles merge into a single, atomic, automated change management process, every catalog will drift, every contract will decay, and every documentation page will lie.