Resolving data silos is a primary goal for every organization. Teams, departments, or systems cannot easily access or share these isolated repositories of structured, semi-structured, and unstructured data.
According to IBM, silos are resulting in 82% of enterprises reporting disrupted workflows, and 68% of data never being analyzed.
Most enterprises have turned to data centralization. This has resulted in bigger, more complex, and harder-to-govern silos that are slower to scale. These centralized data approaches are also less accessible, connected, and trustworthy.
In this article, we cover how agile and enterprise organizations can repair their data silos by rewiring them using data contracts and automation.
.svg)
The Unbroken Cycle of Bigger Silos
Years of investment in centralization have only led to the persistence of silos, exacerbated by:
- Increasing internal and external data sources
- Vague data ownership and fragmented tools
- Growth and acquisitions
- Legacy and modern platform incompatibility
- Insufficient data and metadata quality, making a single source of truth impossible
- Shadow IT growth from employees creating workarounds outside of manual governance systems
- Increasing compliance, access, and security challenges
The resulting disconnected environments cannot share data, which becomes an even greater problem with organizational growth.
Left unchecked, these silos limit agility and create a fractured view of the business, which leads to major challenges with:
- AI/ML and automation adoption
- Business-driven data discovery and analytics
- Market competitiveness and innovation
Nearly half (44%) of respondents gleaned very little value from their data sources, according to the Witboost 2024 Data Management Status Report. Too much time spent attempting to find value in their data leaves a workforce with very little time for true business-driven value creation. This is, after all, the point of all data.
Many organizations have tried to fix silos by razing or dismantling them, but these approaches often make things worse.
Why Conventional Fixes Often Make the Problem Worse
The evolution of data repositories from warehouses and lakes to lakehouses and cloud data platforms (CDPs) has only led to bigger silos. Despite their many strengths, their focus on data centralization is a weakness. This is because they cannot address connected governance, ownership, or accessibility across complex enterprise environments.
Meanwhile, data consumers still struggle to find and trust the right information, and technical teams remain buried in maintenance, integration, and compliance overhead.
All of these data repositories fix some problems and leave others in various ways:
- Data warehouses support organized data structures for things like BI, but they eventually become a rigid, unscalable, centralized silo.
- Data lake scalability and cost efficiency soon turn to data swamps (missing metadata, unclear lineage/ownership, and difficult use beyond the data team).
- Data lakehouses combine the benefits of warehouses and lakes, but they reinforce silos through performance bottlenecks, scalability concerns, governance/access challenges, and vendor lock-in.
- Cloud data platforms (CDP) win on scalability, AI/ML, services, and advanced tools, and yet make data ingress slow and disruptive, which reinforces silos.
Most organizations have built their data management ecosystem around a combination of these solutions. They then attempt to stitch them together to combat the resulting silo complexity.
The “Stitch Everything Together” Approach to Incomplete Solutions
Over the last decade, enterprises have invested heavily in middleware, orchestration layers, and federated architectures designed to integrate their fragmented data landscapes.
The idea of stitching these solutions together is on the right track, but with more tools and solutions, proper integration has simply become harder to realize. While the approach brings them closer to delivering democratized, distributed data management, it stops short of solving the hardest problems of:
- Trust
- Ownership
- Embedded data governance
Looking at some of the fundamental data processes and the latest architecture approaches shows how they fit together—but still fall short of cross-domain data sharing.
Silos will persist and grow without access to a single data platform capable of unifying the mesh. This is true regardless of the underlying tools, architectures, and platforms.
Why? Domain teams often interpret policies differently, which causes inconsistencies in how they build and share data products. This can lead to isolated data products that data consumers cannot combine, preventing interoperability and standardization.
Self-service for data consumers fails because of fragmented or incomplete interfaces and documentation. And while a mesh federates data governance in principle, it can be uneven in practice. This is especially true when the supporting vendor solutions assembled for the mesh don't work as expected.
When These Models Succeed, and Why They Often Don’t
The conventional approaches of centralizing or stitching together have brought organizations closer—but not close enough—to the vision of data democratization.
They ease flow, add flexibility, and introduce valuable concepts like federation and metadata-driven access. Yet they cannot guarantee the connection, governance, access, agility, and trust that organizations require.
Today’s vast enterprise infrastructures are powerful but incomplete without true interconnection, integration, governance, and trust to drive a democratized data ecosystem. Rather than trying to dismantle or raze these investments, the path forward is to rewire data silos so they can work together with embedded governance, contracts, and trust.
Data Silo Rewiring Instead of Razing
Although the challenges of data silos persist, razing them is impractical, if not impossible. Organizations can’t afford to abandon the heavy investments they’ve already made in infrastructure and tech stacks.
The goal should be to rewire these with computational governance, data contracts, guardrails, and automation. This ensures business-driven data discovery benefits, like assured trust, and self-service discoverability across the enterprise in a future-proof way.
Rewiring essentially treats every silo as part of a network rather than an obstacle.
Rewiring Data Silos in 6 Steps
To understand what rewiring looks like in practical terms, here are six steps organizations can take to transform their data silos.
1. Autonomy with Accountability
Data owners and producers must have control over their data in products and over how it’s used in data projects through embedded quality and governance controls. These same aspects serve data consumers, which is the foundation of autonomy with accountability.
2. Embedded Governance
Organizations must have a computational governance framework to embed governance into the data product lifecycle. This should be a data governance shift-left approach, which applies governance as code from the data control plane and pipelines to the market plane with products and project workflows.
This integration across the data lifecycle also sets clear governance guardrails via scalable and universal automation.
3. Data Contracts and Guardians
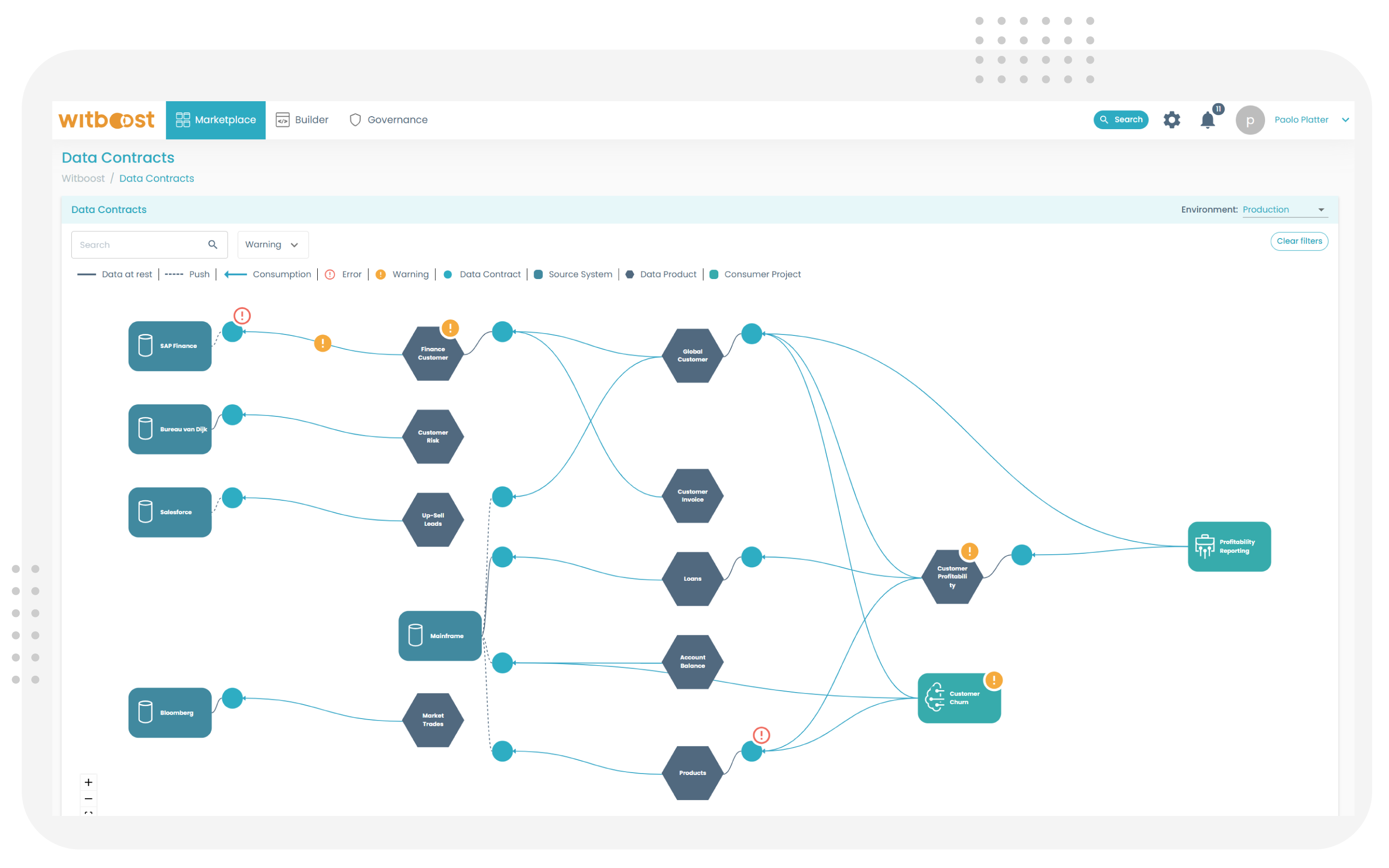
Every exchange of data requires clarity. Data contracts define the schema, quality, and SLA expectations, while guardians enforce them at runtime and deploy time.
This approach:
- Prevents drift
- Maximizes data governance and trust
- Enforces data contracts for interoperability so silos remain connected
- Ensures data consumers have clear usage rules and access protocols
4. Metadata-Driven Visibility
Metadata should be rich, consistent, and automatically updated; it should also always be aligned with data and lineage. This allows consumers to explore, understand, and confidently use data products no matter where they live.
5. Self-Service Through a Marketplace Experience
Democratization requires an agile user experience based on their preferred tools. A data marketplace model lets consumers “shop” for governed data products, reducing cognitive load and speeding adoption.
6. Standardization Without Rigidity
Standard templates and reusable blueprints allow consistency at scale while leaving room for teams to adapt to their domain needs for greater innovation and insights.
Rewiring Is About Connection, Not Collapse
With data silos, rewiring is all about connection to ensure data silos across architectures, platforms, tool use, and locations are part of a governed, visible, and accountable network.
In this model, silos stop being barriers and start functioning as nodes in a larger system of access, agility, and trust.
Let’s now see how these capabilities and requirements are practical and achievable with Witboost.
How Witboost Rewires Silos

Enterprises need a future-proof way to rewire their existing silos, regardless of the underlying data architecture and IT systems that entrench those silos.
The Witboost platform does this by embedding enterprise-scale computational governance and connectivity across your existing architecture via the following attributes.
Data Contracts as Code
Data contracts in Witboost are formal, version-controlled declarations of what a data producer promises to consumers: schema, freshness, quality thresholds, and SLA expectations.
Defining data contracts as code lets organizations automate them for data quality. The system automatically validates data contracts, which are embedded with data pipeline artifacts and stored in Git at build time. This guarantees clarity between data producers and consumers by reducing disputes over data quality, freshness, and definitions.
Contract Guardians (Runtime Enforcement)
Guardians are lightweight runtime agents embedded in the data product consumption layer. They make sure live data still meets the deployed contract by ensuring schema integrity, freshness, and quality constraints.
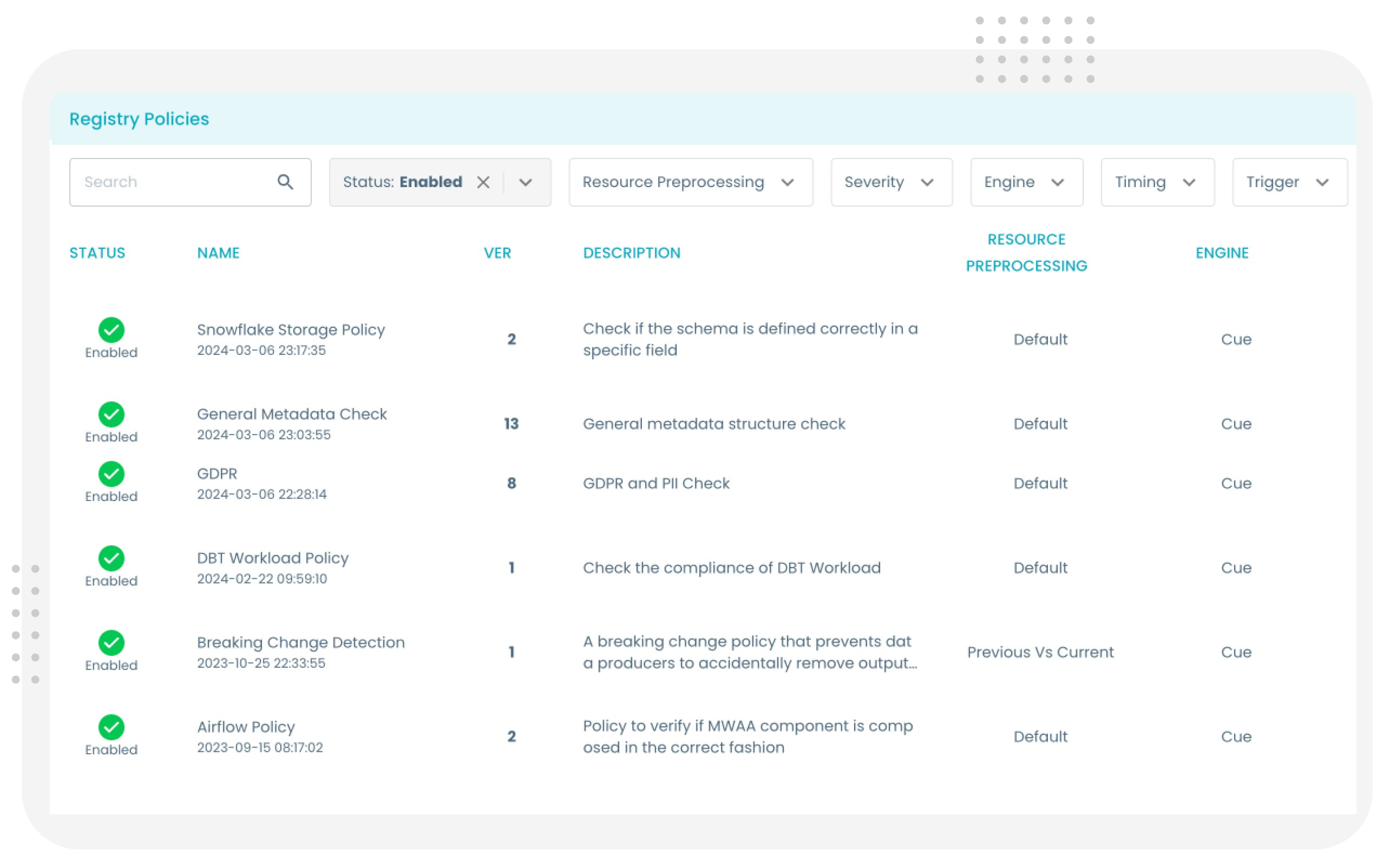
Data Governance Shift-Left (Embedded Policy as Code)
Data governance shift-left reframes data product governance from a post-production checkpoint to complete data lifecycle management. The Witboost platform embeds policy as code to validate and update compliance rules, metadata (metadata as code), data lineage tagging, access policies, masking, and more at deploy and runtime.
All of this overcomes the limitations of:
- Centralized models (warehouses, data lakes, data lakehouses, CDPs)
- Decentralized models (data meshes, data fabrics, ELT, and integration hubs)
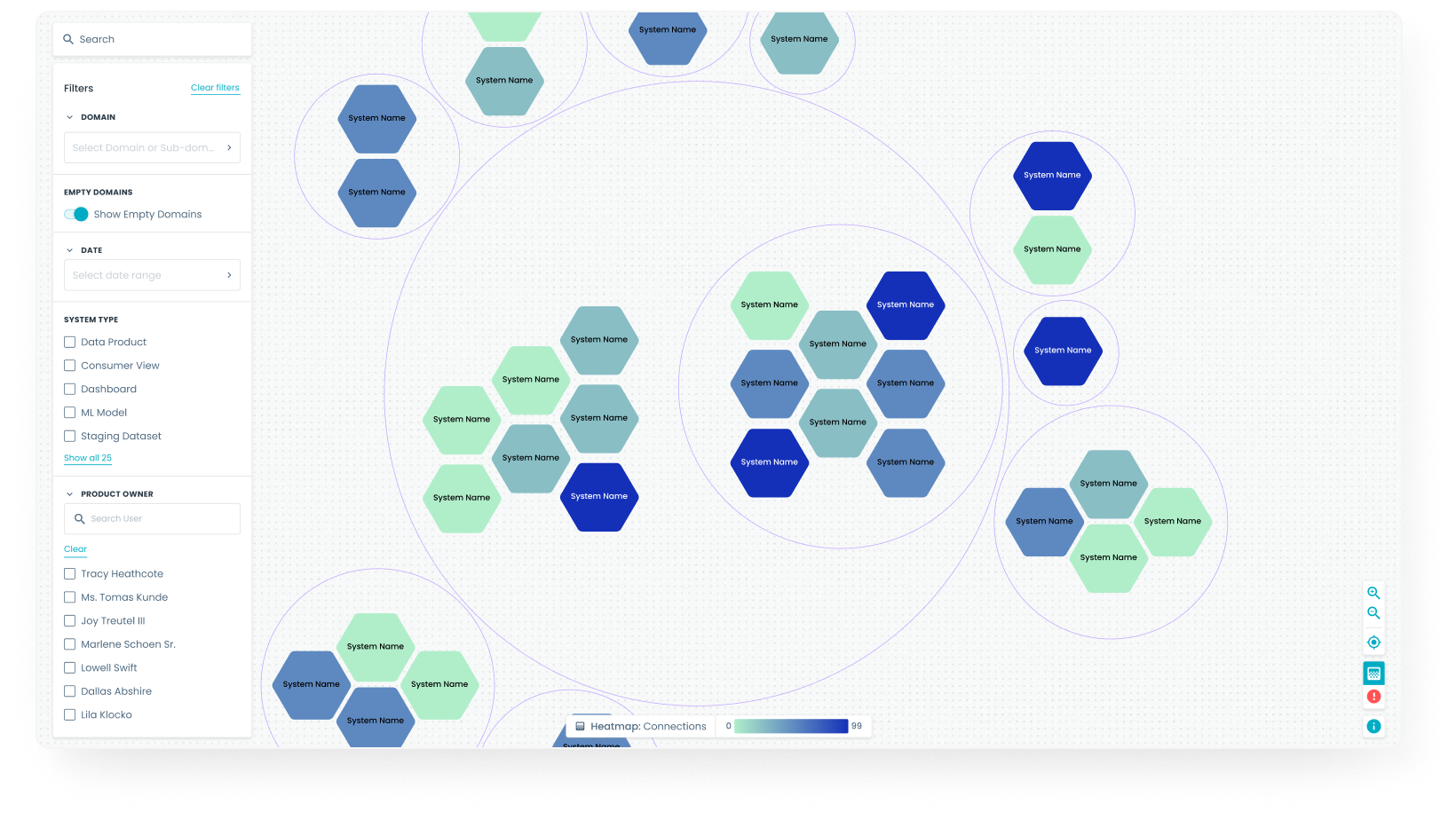
Metadata-Driven Visibility & Marketplace for Data Products
The Witboost Market Plane creates a discovery and consumption layer that surfaces data products with rich metadata (ownership, lineage, schema, quality, contract status).
It automatically updates and constantly aligns metadata across all products and overcomes existing catalog limitations. Consumers browse and request access through an intuitive interface.
Business outcomes:
- Empowers users with a familiar shopping-style experience
- Reduces the time from discovery to insight, enabling true self-service
- Surfaces only relevant data products
Technical outcomes:
- Metadata, lineage, and ownership that flow automatically into the marketplace
- Bi-directional sync with existing catalogs, preventing duplication and ensuring currency
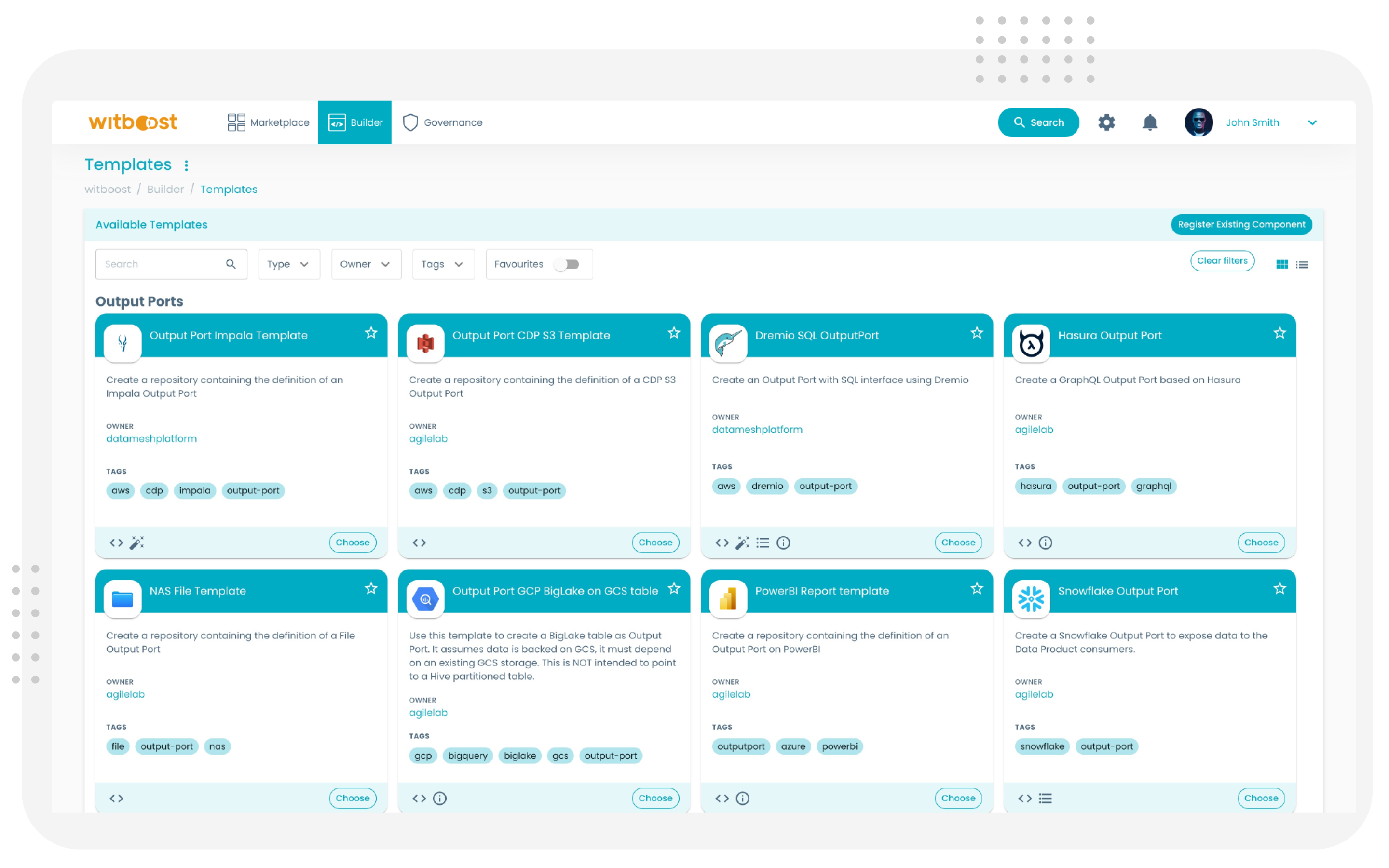
Modular Build Templates & Provisioners
Witboost provides pre-built, Git-backed, reusable templates for data product pipelines, metadata registration, contract scaffolding, and governance embedding.
Provisioners automate the deployment and management of data components on target infrastructure. They act as “tech adapters,” translating template-based requests into actions on specific technologies like Snowflake, Databricks, and many others.
Provisioners also interact with the marketplace and catalog to register and update metadata about new data products.
Business outcomes:
- Enables rapid onboarding and consistent output across teams
- Provides automatic data contract enforcement via Guardians and standard guardrails with flexibility
- Maximizes speed, governs access, ensures accuracy/standardization, and ensures interoperability by rewiring silos
- Facilitates the creation of interoperable data products for easy integration and use of data from different domains
By promoting these principles through standardized, automated, and governed processes, Witboost templates help organizations shift from centralized data management to decentralized, domain-driven ownership.
This integrated data landscape rewires data silos for interconnection to improve data sharing and collaboration across the enterprise.
AI Copilot (Witty)
Large language models (LLMs) power the Witboost AI companion to assist users in writing metadata, generating contract definitions, suggesting schema descriptions, and classifying data. Plus, it works contextually within the platform.
Business outcomes:
- Lowers the barrier for non-technical users by assisting with documentation, data contracts, and metadata
- Increases adoption and consistency across domains
Witboost’s Real-World Results
An analysis by Forrester Research of the real-world impact of Witboost has shown measurable business impact:
- Time-to-market for new data products cut from 24 months to 6 months
- $7.7M in efficiency gains per program
- ROI of 320% and net present value of $11.43M
- 40% reduction in effort duplication, freeing teams to focus on innovation
These results highlight a fundamental shift, where data silo networking creates an agile, governed, and democratized data ecosystem.
Rewiring Silos for Tomorrow’s Connected Enterprise with Witboost
The story of data silo challenges in enterprise environments has been one of fragmentation. Warehouses, lakes, fabrics, and meshes built with the best of intentions leave organizations with bigger, more complex silos.
While tearing down silos is neither practical nor effective, data silo rewiring transforms them into connected, trusted, and governed self-service networks. Witboost delivers this by:
- Maximizing data contracts and embedding data governance, guardians, metadata, and automation directly into the data product lifecycle
- Creating a data governance platform via data governance shift-left, driven by context-aware computational policy as code, and metadata as code
- Iteratively using templates and policy automation so the system adapts as business and regulatory needs change
- Including marketplace modules to make data products self-service and consumable
Witboost’s modular, policy-driven design prevents organizations from being locked into a single architecture or vendor. Instead, they operate on a platform that adapts as architectures, tools, regulations, and demands change.
The enterprise data landscape will only grow more complex as agentic AI, hybrid cloud, IoT, and edge computing expand. Witboost creates an actual path to transform data silos into a network of connected, trusted, and agile data products.
The result is a future-proof, democratized data landscape that balances control, agility, self-service, and trust at scale for data owners, producers, and consumers.