Data Product
How to Build Data Fabric from Data Products
Learn how to build a robust data fabric using data products to enhance metadata quality, governance, and integration across your organization.
Explore the power of synthetic data in Data Mesh architecture. Learn how to leverage Tonic.ai in Witboost for automating data operations.
Synthetic data is revolutionizing data management and utilization, enabling businesses to conduct thorough testing, prototyping, and innovation while ensuring privacy and security. By integrating synthetic data into data mesh frameworks, organizations can decentralize data ownership and improve data operations. Using Witboost together with tools such as Tonic.ai, you can automate the generation and integration of synthetic data, creating scalable and secure data ecosystems. This seamless integration not only enhances data accessibility and documentation but also accelerates development cycles, facilitating faster and more efficient innovation.
Synthetic data is artificially generated data that mimics the characteristics and structure of real-world data. Unlike actual data, which is collected from real-world events, synthetic data is created using algorithms and simulations. This type of data plays a crucial role in various fields due to its flexibility and privacy-preserving properties.
The data mesh approach emphasizes decentralized data ownership, treating data as a product, managed by cross-functional teams. Synthetic data can play a pivotal role in this architecture in two main ways:
By providing synthetic data samples at the output ports of data products, teams can document the structure and expected format of the data without revealing any private information. This makes it easier for downstream consumers to understand and integrate with the data product.
There are more use cases which include data product regression testing, but we will dive into this topic on another occasion.
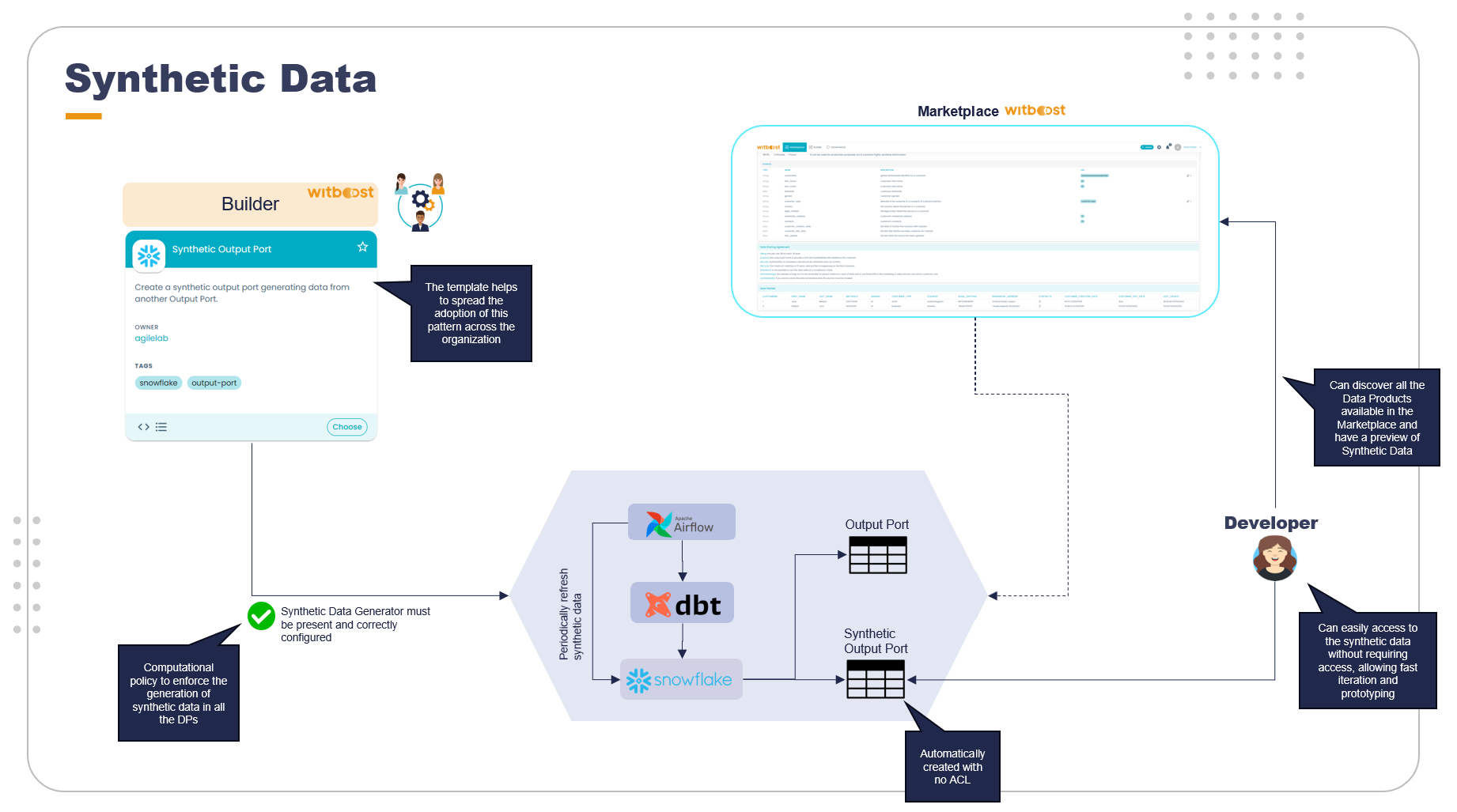
Let's take a closer look at what both do and how their integration works.
Tonic.ai is a powerful tool designed to create realistic synthetic data. It leverages advanced algorithms to generate data that preserves the statistical properties and relationships of the original datasets. Tonic.ai is known for its ability to maintain data integrity while ensuring privacy, making it ideal for use in sensitive environments.
Witboost is a platform that streamlines complex data projects, enhancing productivity and ensuring compliance and governance by design. By integrating Tonic.ai with Witboost, organizations can greatly simplify the process of generating and using synthetic data within their data mesh architecture, creating a repeatable pattern that can be leveraged in a decentralized context, making sure that every domain is taking care of protecting their sample data.
The integration works as follows:
When a data product is deployed all the output ports must be documented and tagged with proper information to allow the synthetic data generation. Each field must be marked with specific tags that will be enforced by the computational policies of Witboost to ensure the configuration has been made
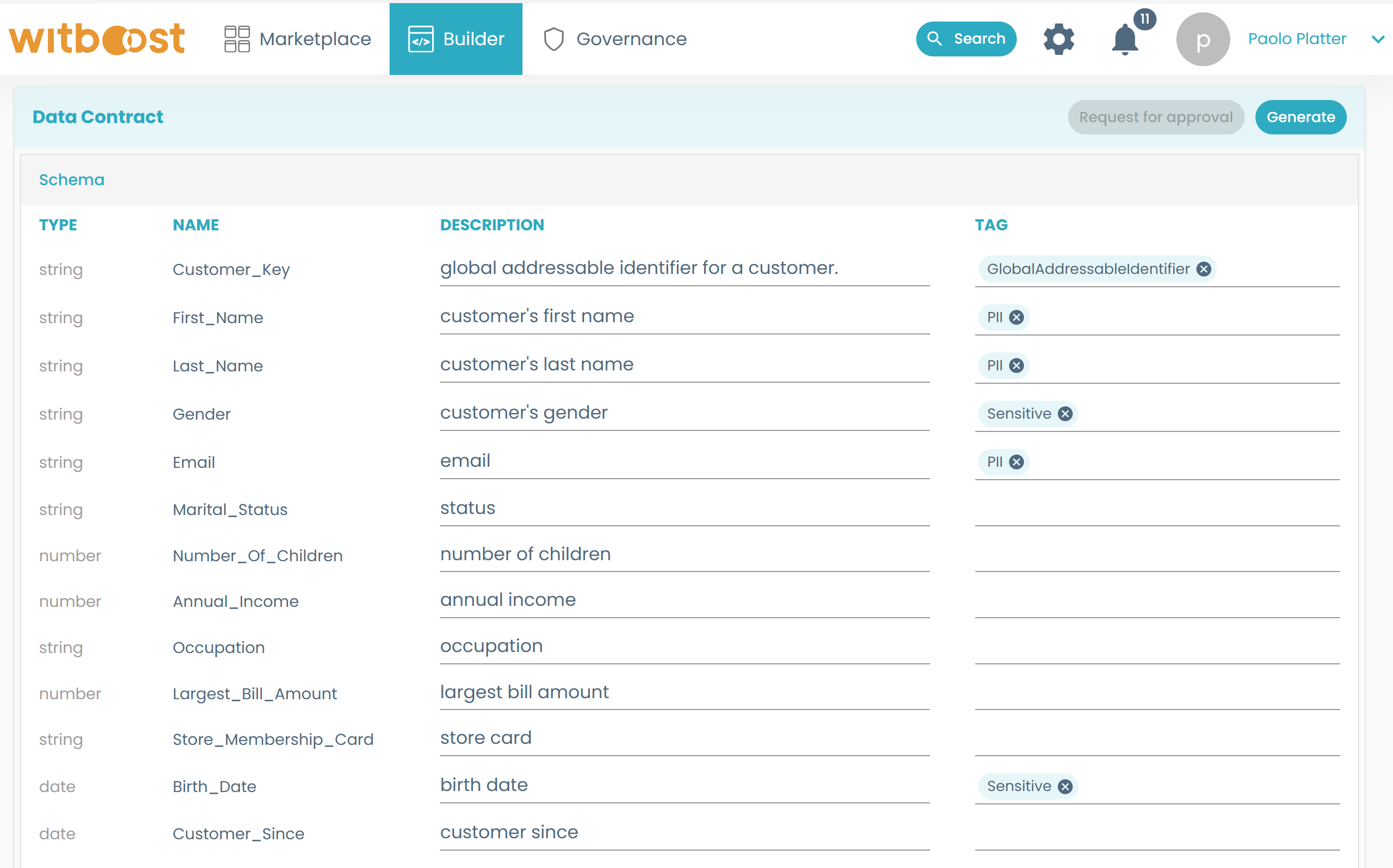
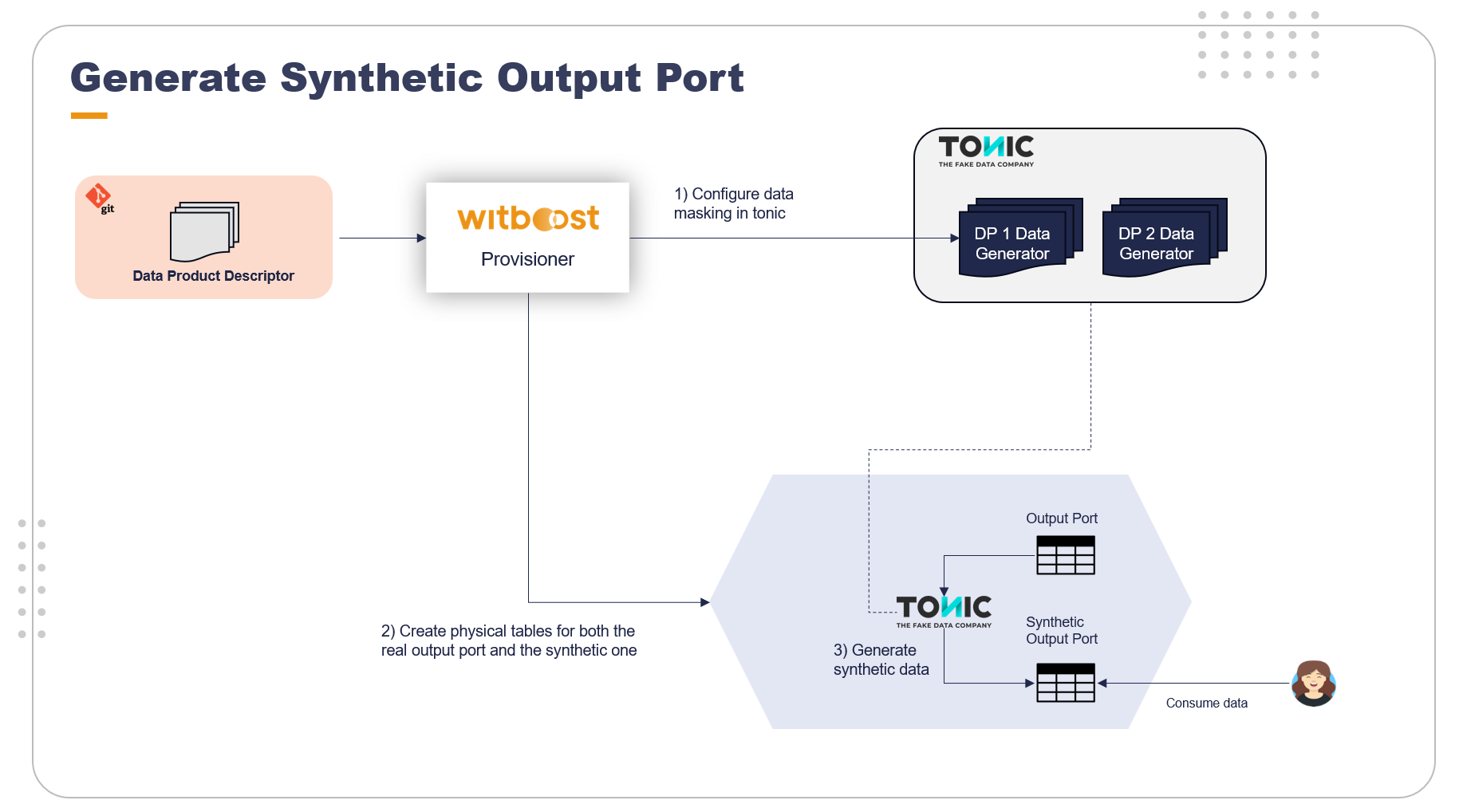
When it comes to deploying a data product, Witboost is going to configure the Tonic.ai workspace by creating specific settings for each data product and output port.
The real output port is configured as the source, while the synthetic one that must be generated is configured as the destination. Witboost automatically creates all the replacements (this is the name of data transformation configurations) and saves them in Tonic.ai.
When the data product is live, Witboost triggers a data generation command to initialize the synthetic output port. This operation can then be repeated by the data product itself during its lifecycle.
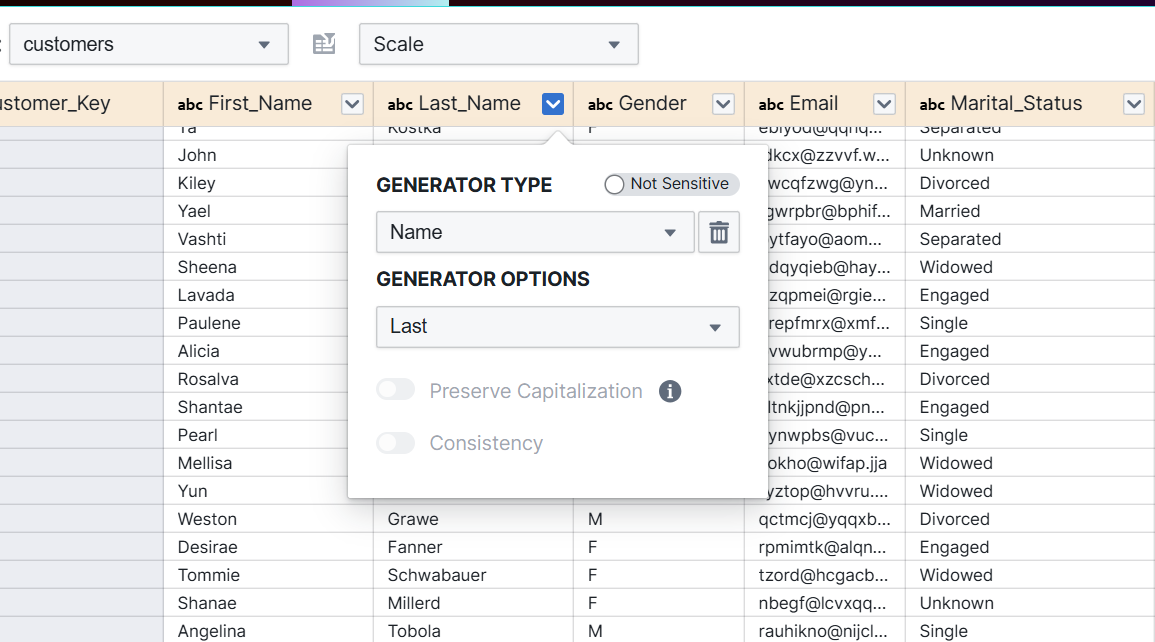
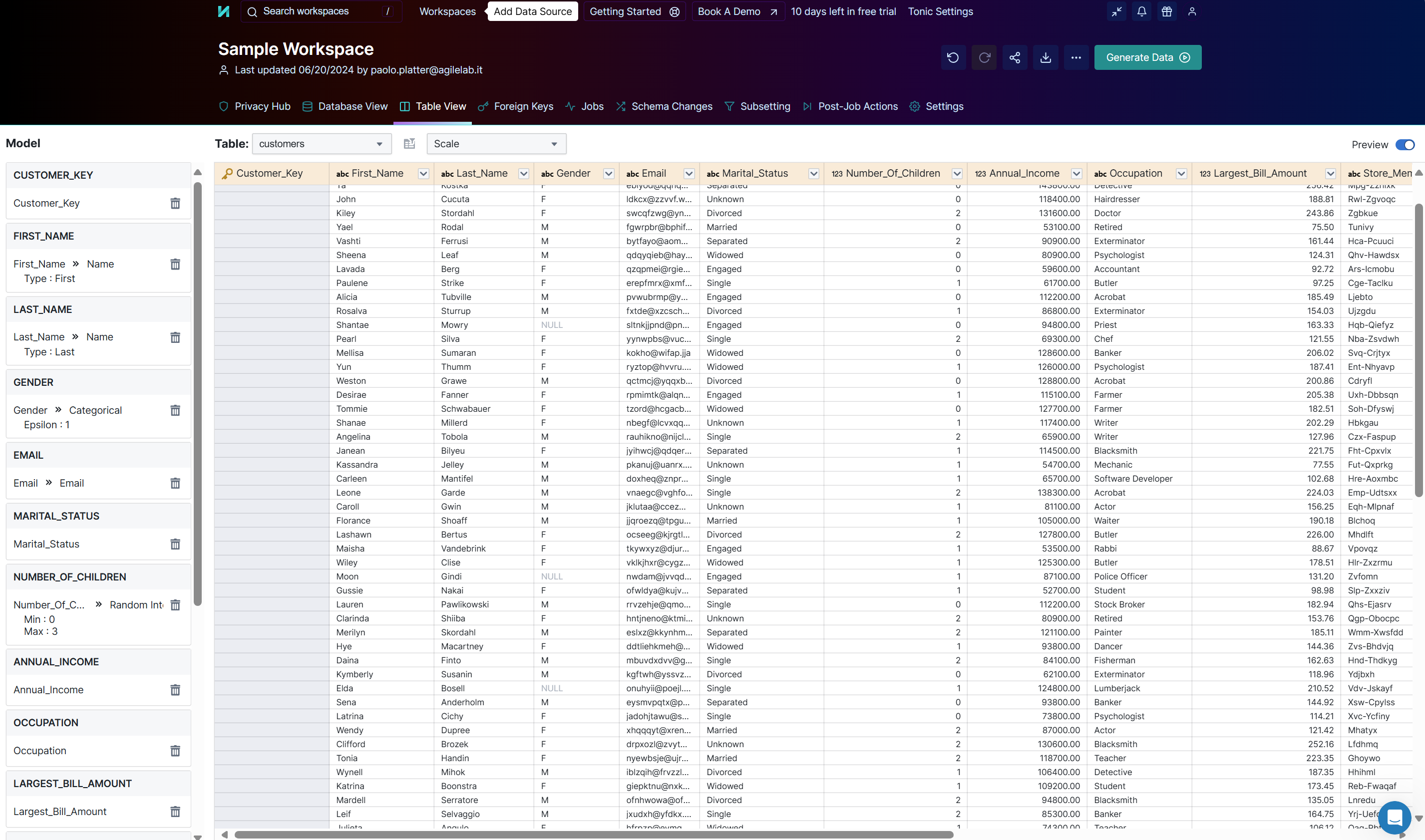
This is how Tonic.ai looks like when a new source is configured
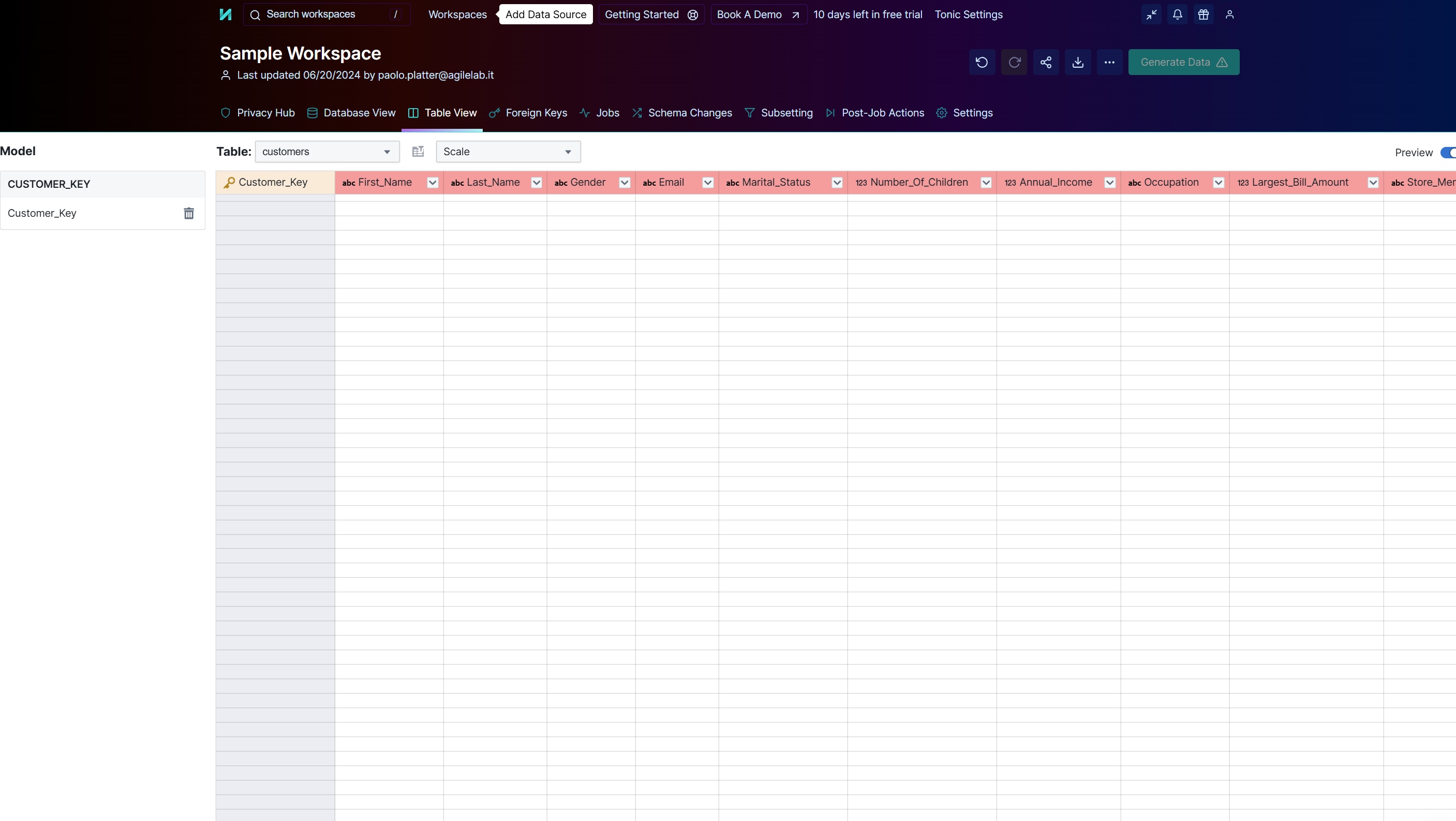
And this is how Witboost can configure it and trigger the data generation without requiring the end-user to log into it, removing a lot of cognitive load and manual operation.
A similar pattern can be leveraged to improve the automation of data documentation, such as creating a realistic sample of data to publish in the Witboost marketplace.
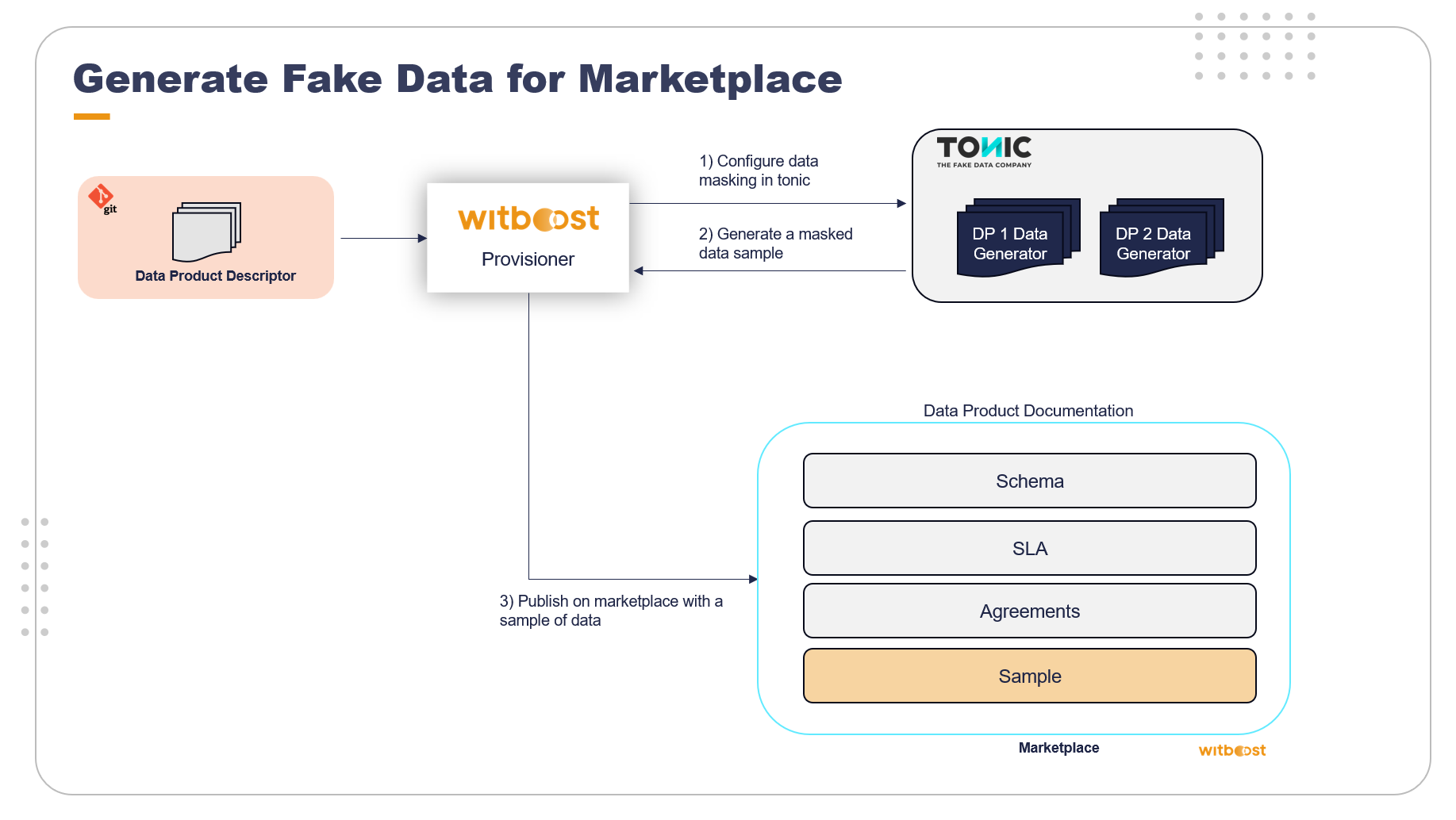
Also, in this case, the effect is a better experience for the data consumers and less effort for the data product team.
This integration not only enhances the documentation and accessibility of data products but also ensures that sensitive data remains secure. By automating these patterns, Witboost and Tonic.ai enable faster development cycles and better data governance.
For more details on how to implement this integration, you can refer to the open-source repository available in our Starter Kit.
In summary, synthetic data is a versatile and powerful asset in modern data architectures, particularly within a data mesh framework. By leveraging tools like Tonic.ai and integrating them with platforms like Witboost, organizations can enhance their data operations, improve security, and accelerate innovation.
Learn how to build a robust data fabric using data products to enhance metadata quality, governance, and integration across your organization.
Data Mesh is completely changing the perspective on how we look at data inside a company. Read about what Data Mesh and how it works.
Balancing autonomy and governance in data engineering is crucial for scaling data products. Learn how Newton's laws offer a unique perspective on...