In the ever-evolving landscape of data management and architecture, the Data Mesh approach has gained significant traction as a promising paradigm shift. To shed light on this fascinating concept and delve deeper into its core principles, the Data Mesh Learning Community recently organized an engaging Q&A session with Paolo Platter, our Co-Founder and CTO.
Hosted on the vibrant platform of the Data Mesh Learning Community's website, this insightful Q&A provided a unique opportunity for data enthusiasts, architects, and practitioners to glean firsthand insights from Paolo.
Drawing inspiration from one of his influential blog posts, Paolo explored the transformative potential of the Data Mesh approach and shed light on its key components.
Read on for the Q&A discussion.
Q&A Session
Data Mesh Learning: Thank you, Paolo, for chatting with us! What are your thoughts on the data mesh architectural framework when it comes to our industry’s changing data management needs?
Paolo: Companies that have started the journey toward implementing a data mesh architecture need to seriously consider making their design as future-proof as possible to sustain organizations’ dynamic data strategies.
Data Mesh Learning: In your article, you mentioned that, like every significant industrial transformation, a data mesh could–and should–survive at least 10 years. How can companies future-proof their data mesh?
Paolo: Data mesh is a strategic and transformative initiative; its architecture must be evolutionary to embrace inevitable change and survive even against a core technological change.
Embracing the data mesh paradigm is an investment that, if done right, should pay off for years.
Data Mesh Learning: In your article, you mention several ways to ensure the longevity of your data mesh architecture: 1) avoiding lock-in, 2) decoupling your data strategy from market risks, 3) avoiding silos, and 4) prioritizing interoperability. Can you walk us through each one?
Paolo: First, the entire data mesh paradigm is based on a technology-agnostic approach, so the biggest mistake I see data teams make is when they stake their data mesh implementation on a single holistic data platform or vendor.
This begs several questions, like:
How are observability and data contracts exposed if their platform doesn’t offer APIs?
How is output ports’ polyglotism granted if only topics are supported by the platform?
Are data products on these platforms atomic and independent deployment units, including infrastructure, data, metadata, and code? and
If all the domains must use the one-and-only technology and platform, are we decentralizing ownership and providing autonomy?
You can use one platform or technology as the main backbone—or to achieve a minimum viable product—but I recommend that data teams avoid getting locked into a single platform or vendor.
Data Mesh Learning: Can you explain how getting locked in with data platform vendors can affect the longevity of data mesh architectures in the market?
Paolo: Your data strategy should be de-correlated to market risks. The goal is to generate business value for your company, and that value should not be affected by external factors. Unfortunately, the recent events around Silicon Valley Bank and other banks have shown us how fragile the technology ecosystem can be.
Another example of market risk is Hadoop. We had five or six distributions in its early years, but only one has survived today.
Or do you remember MapR? They had a good customer base with tier-one enterprises. In 2014 they raised $110 million, but by 2019 the company had shut down. The migration for those locked in with their components was a nightmare. In most cases, teams had to rewrite all use cases completely.
No one can predict the future. So a 10-15 year industrial plan can’t depend on only one or two VC-backed tools. That’s too much risk.
Data Mesh Learning: Speaking of tools, you mentioned that teams often find themselves stuck in technology silos.
Paolo: Yes, let me paint a picture. Imagine this scenario. You’re a big enterprise that’s planning to implement a data mesh.
You created the enterprise data warehouse with a specific vendor 10 years ago, embedding business logic with a proprietary PL/SQL. After five years, you started facing issues around scalability, ingestion rates, and time to market.
Then, you decide to leverage a Hadoop-based data lake platform to address streaming and cost-effective big data use cases at a petabyte scale. While implementing them, you realized the need for the following:
New tools (data exploration, data quality, data catalog, etc.), but now data is not stored in an RDBMS and is accessible through SQL or JDBC;
New skills to exploit the computing polyglotism we now have;
New governance rules and processes because the data lake has different requirements and goals; and
Duplicating data and business logic from the data warehouse to the data lake due to correlation needs (e.g., customer info joined with credit card transactions).
At this point, the data lake initiative (with the original aim to unlock new business insights also enabling ML/AI-driven analytics) turned into a completely new data platform with duplicated data, a different tech stack, skills, processes, and policies.
The original CAPEX investment has tripled, while OPEX costs have multiplied tenfold because you now have two giant silos fighting for budget and use cases, offering the worst-ever user experience for data consumers. This all happened because of technology lock-in.
Data Mesh Learning: How do you fight against lock-in?
Paolo: First, don’t couple teams with technology. Conway’s law says organizations design systems that mirror their own communication structure. In other words, if you have two siloed teams, you will end up with two data silos. So don’t couple teams with technology; connect them with business objectives instead.
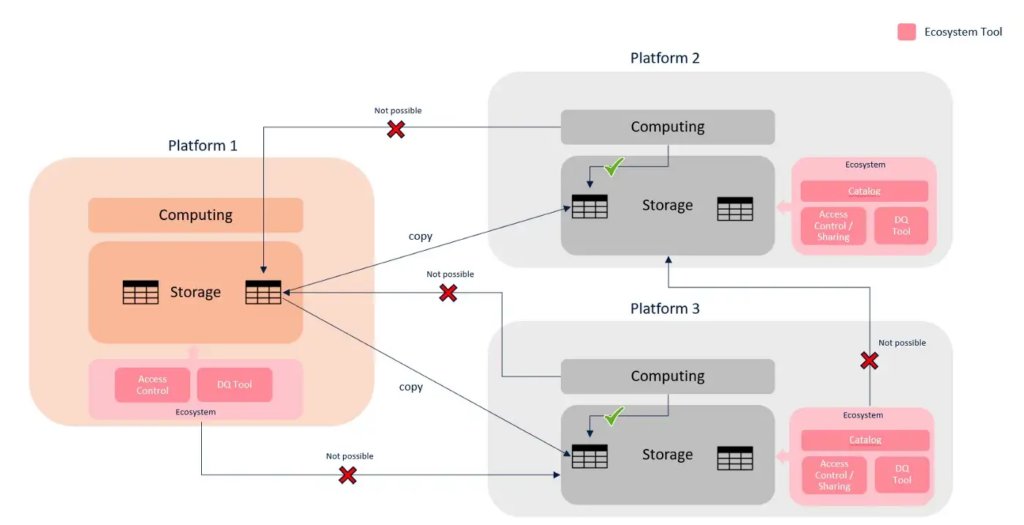
Second, don’t couple tools (for data quality, cataloging, access control, etc.) into a single, all-in-one platform. That increases lock-in and decreases interoperability. The idea of data mesh is to make all data available and correlate it across domains to generate value.
Data Mesh Learning: What are the alternatives if a team already has multiple technological silos?
Paolo: You have three options:
Select a(nother) new all-in-one technology platform, plan for a significant migration, and rewrite everything. Maybe this platform now offers lots of native capabilities and proprietary interfaces. Of course, they will speed up the time to market, but there’s a serious risk of creating just another silo because of the lack of interoperability.
Re-use one of the existing platforms, changing the practice, and reducing the impacts but still locking into a silo with (probably) no capabilities to expand and evolve the technological landscape in the future.
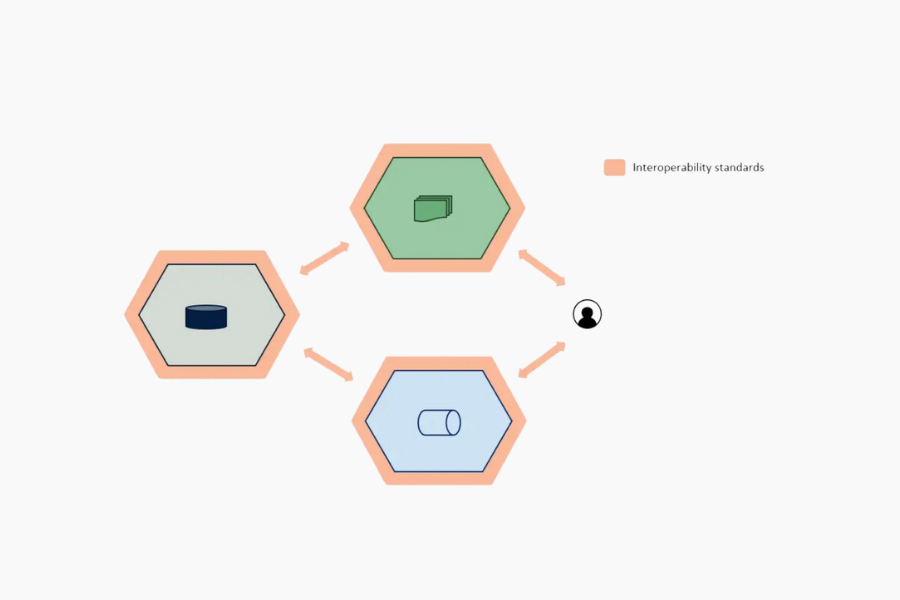
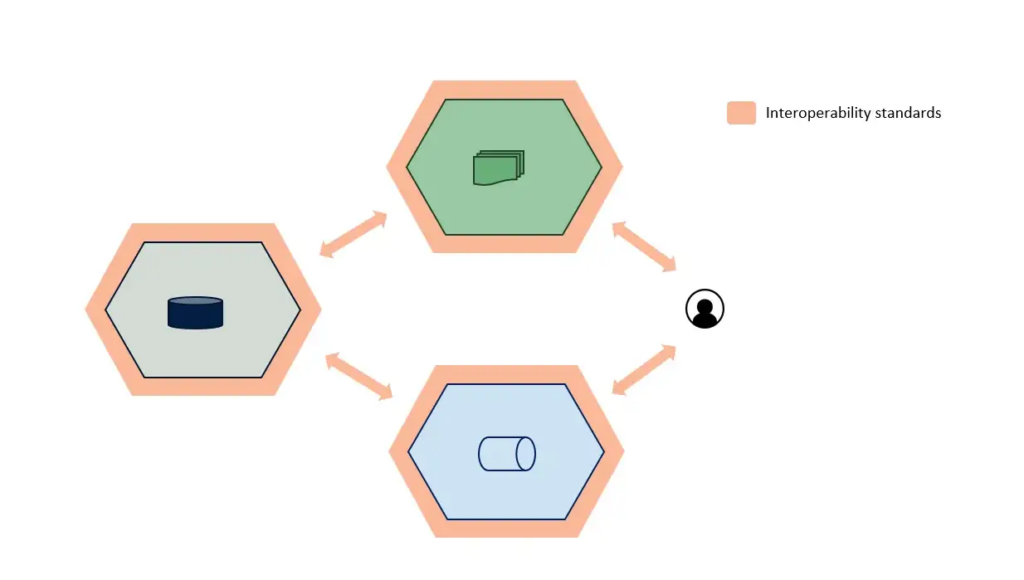
Create interoperability standards. Separate technology and products, use open protocols, and assemble your necessary components. This will allow you to leverage existing technology and introduce new ones in the future. For instance, to develop business logic, you should use only frameworks highly independent from the underlying data storage technology to reduce the overall coupling.
Data Mesh Learning: That leads us to your last point: prioritizing interoperability.
Paolo: Exactly. Interoperability implies having clear standards:
For exchanging data products’ data, metadata, formats, output ports’ protocols, observability info, data contracts, and more;
For open, extensible, and decoupled to any specific single technology; and
For semantic linking, avoid centralized lock-in on single MDM systems.
Data Mesh Learning: Any last advice for organizations implementing data mesh?
Paolo: Make it future-proof, and remember:
Don’t use native facilities (offered by tools) to set interoperability standards. Instead, even if you have just one technology right now, design everything to be able to change it or add one without breaking contracts and standards.
Decouple storage from computing. You should provide the domains the freedom to choose their preferred (interoperable) compute engine, to process in zero-copy fashion data made available in different data storage technologies.
Try to be declarative as much as possible, adopting open standards.
Rely on open and widely adopted protocols to share data across data products via output ports.
Set your standards for control ports and observability API.
Don’t couple governance and security processes/policies with specific technologies/data platforms.
Focus on practice and developer experience more than tools and technologies.
Explore the latest expansion of the Witboost Starter Kit with Azure Data Factory integration, simplifying data ingestion and orchestration for Azure...