To distribute the ownership of data modelling to multiple data teams, we need to define practical guidelines because not all of them can extract data modelling golden rules from the Data Mesh principles and apply them with consistency.
First of all, let’s talk about different kinds of data domains and Data Products. The Data Mesh reference book by Zhamak Deghani talks about three types of data domains:
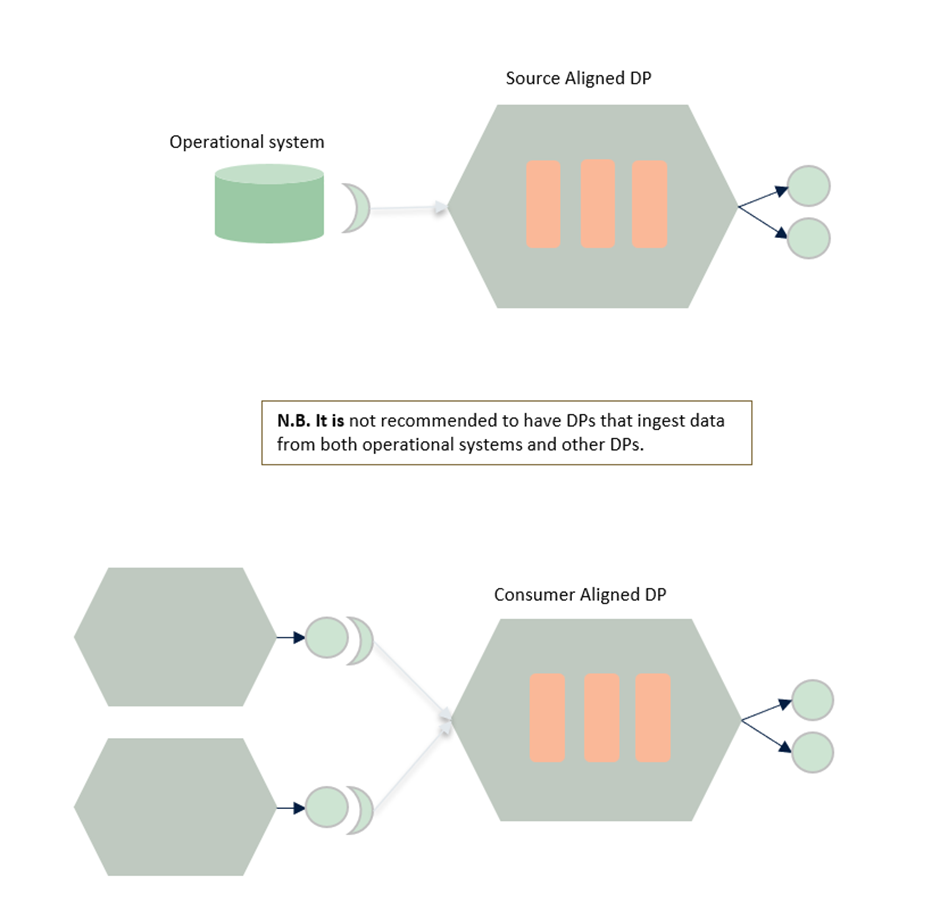
Source-aligned data domains should align 1:1 with the domains defined in the operational plane.
Aggregate data domains.
Consumer-aligned data domains should align with business processes that extract value from data to serve an analytical use case.
When it comes to aggregated domain data, in the book, there is a side note (warning):
I strongly caution you against creating ambitious aggregate domain data — aggregate domain data that attempts to capture all facets of a particular concept, like listener 360, and serve many organization-wide data users.
Such aggregates can become too complex and unwieldy to manage, difficult to understand and use for any particular use case, and hard to keep up to date. In the past, the implementation of Master Data Management (MDM) has attempted to aggregate all facets of shared data assets in one place and one model. This is a move back to single monolithic schema modeling that doesn’t scale.
Data Mesh proposes that end consumers compose their own fit-for-purpose data aggregates and resist the temptation of highly reusable and ambitious aggregates.
I would take this warning to the next level: aggregate domain data do not exist.
There are several reasons for this ambitious declaration:
The “aggregate” term is colliding with the “aggregate” concept of DDD that in the Data Mesh should be mapped 1:1 with a Data Product (see How to identify Data Products) and, to me, is generating a bit of confusion.
In the real world, there are no aggregate domains; domains in DDD represent a space of problems solved by business processes. An aggregate domain data does not embed business concepts or business logic but is only a different physical representation of other domains’ data.
We need to have clear definitions to help people embrace concepts. Opening the door for a concept that, if abused, brings back to the monolithic approach is inconsistent and undermines the Data Mesh principles.
How much can a domain stress the aggregate domain data concept? Who will decide about that? Do we have a rule of thumb?
One of the characteristics of a Data Product is “valuable on its own,” meaning it should deliver business value by itself. Still, it should add business value to the ecosystem to be considered valuable. An aggregate domain data joining and aggregating data to generate an intermediate technical step is not adding business value.
Suppose instead we are transforming other Data Products into a brand-new business concept, reusable across the company. In that case, it is fine, but I don’t see substantial differences with consumer-aligned Data Products.
Based on the current definition of aggregate domain data and consumer-aligned domain data, a Data Product created for a specific use case (consumer-aligned) could turn into an aggregate one because being used more broadly and comprehensively than before. It becomes impossible to define clear boundaries to classify a data product as an aggregate domain data or a consumer-aligned one.
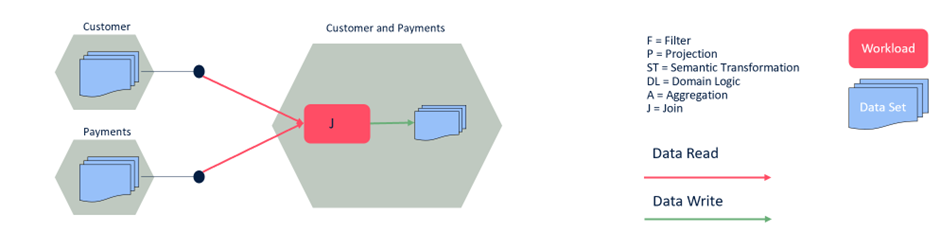
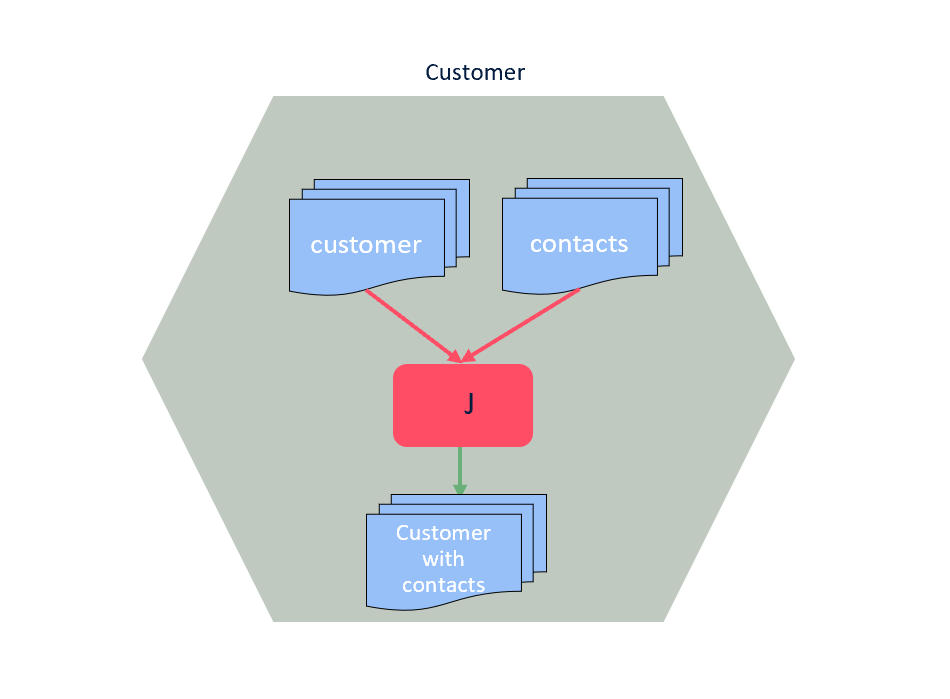
In the following scenario, “the customer and payments” Data Product is just the result of a join, merging of information from two different data domains, without any specific domain logic or semantic transformation. In my opinion, this is not even a Data Product because:
It is not adding business value
It is just a technical step to improve performances and re-use
Aggregate domain data is not adding business value.
My suggestion is to rely only on source-aligned and consumer-aligned Data Products, with the following simple rule:
Source-aligned Data Product: is ingesting data from an operational system
Consumer-aligned Data Product: is only reading data from other Data Products.
I suggest to double check also this article by Roberto Coluccio.
Don’t redistribute data coming from other domains
Another critical concept for Data Product modelling is the “no-redistribution” principle, introduced in Data Management at Scale (oreilly.com), by Piethein Strengholt.
This principle states that a domain should never redistribute data coming and belonging to another domain unless you are changing its semantic meaning. In DDD, when a piece of information crosses the boundaries between two domains and changes its importance, we are talking about context maps.
Data redistribution should be allowed and encouraged only if paired with context map information. Otherwise, consumers will get confused about who is the actual owner and master of a certain piece of information.
There is a vast difference between consuming and using specific information and exposing it. It should be allowed to copy and store information from other domains within a Data Product but not to share them through the output ports.
Suppose you copy the data from another domain (copy implies persisting it, not just using): in that case, you immediately become accountable for managing it according to compliance and security constraints because data duplication results in new ownership.
When you approach the data modelling of your Data Product it could be helpful to proceed in this way:
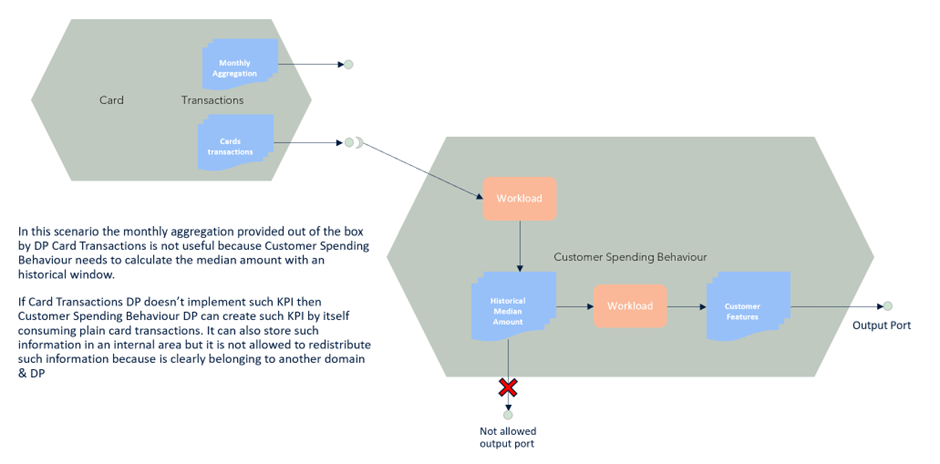
If it is possible not to copy the data from other domains but use them and process them on the fly, go with that.
Otherwise, if for some reason you need to accumulate them, please do it in the internal storage of the Data Product, do not share them through output ports, and pay attention to managing them properly, taking into account compliance and governance concerns.
If you are transforming such information and you need to redistribute it with a different semantic meaning, pair it with the proper context maps information.
Last option, you can duplicate information if it is strictly helpful to make your dataset more meaningful and comprehensible to your consumers. The duplication should not be more than 5%-10% (rule of thumb) of the total number of information elements. The overall goal of the dataset is different from the source one.
Solving the Denormalization and Aggregation dilemma
Another dilemma is about aggregations and denormalization. As we know, denormalization in DDD and Data Mesh is fine, but it is unclear if you need to create a new Data Product to implement it.
My short answer is no.
Until you are not creating new data and new knowledge, you should stay within the bounded context of the same Data Product.
This principle is valid only when you are managing the same piece of information.
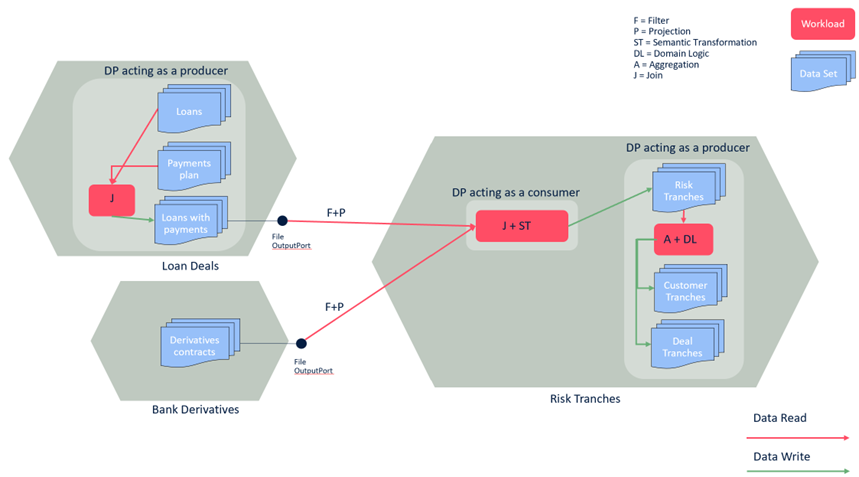
We can say that a Data Product has two souls. When it reads data from other Data Products or external sources, it acts as a consumer, while when it writes data for output ports acts as a producer. This is useful to understand better the general rules in the end.
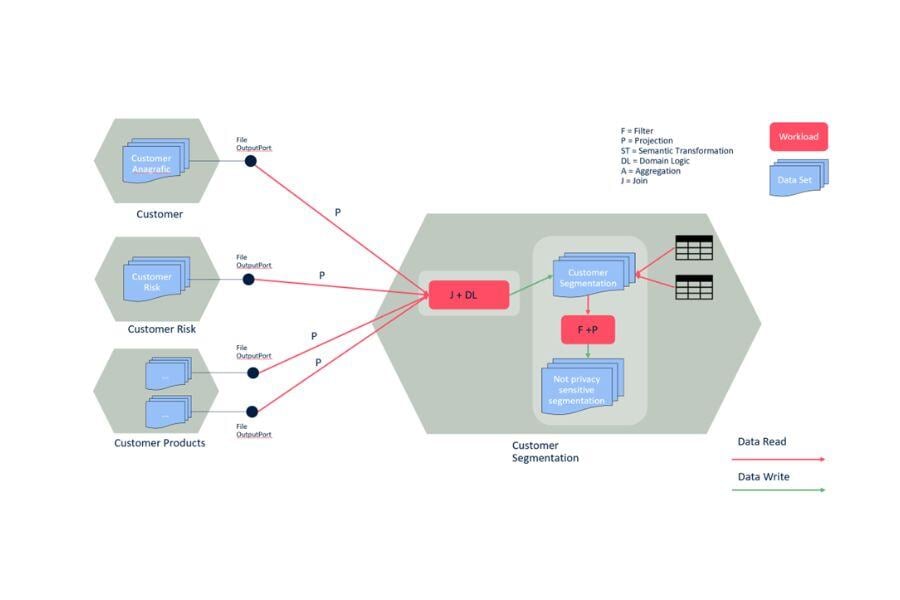
Suppose you are generating a new business concept that belongs to a specific domain (Risk). If you need to join multiple data domains and apply some semantic transformation (that is always hiding domain logic), then it is worth creating a new Data Product because you are creating a brand-new business concept. For example, in Risk Tranches we convert installments coming from in risk components, that is a semantic transformation.
Otherwise, if you are aggregating data that already belong to your Data Product, even if you apply specific domain logic, it means you are in the same bounded context. It means you have to add a new Output Port to the same Data Product, because probably you only need to apply some denormalization to make the data more consumer-friendly.
How to correctly apply Filters and Projections
One question I always get is: “Do I need to create all the possible views of my data for my consumers?”
The short answer is no.
This question comes because today, to align not interoperable data silos, each data producer is exporting data sets.
The producer maintains several export processes and snapshots based on customer requirements. This pattern always leads to data integration, operations and maintenance burdens. This is totally against the product thinking that Data Mesh requires.
A product manager is not implementing features based on individual customer requests; the product manager tries to validate features against the addressable market to achieve product market fit.
When a producer is exporting data according to consumer requests (maybe coming from a different domain), there is a high risk that the producer will end up implementing some domain-specific logic or semantic transformation belonging to the consumer. This would be a clear violation of the domain-oriented ownership principle.
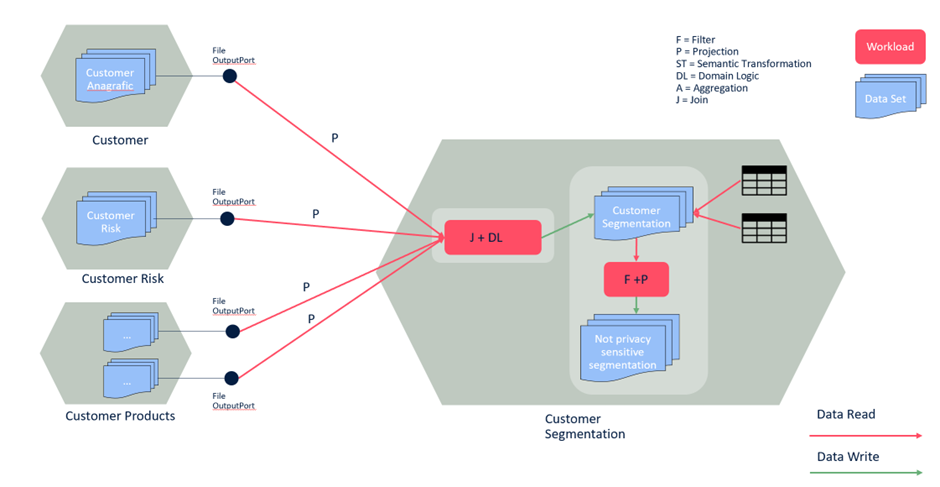
If we implement interoperability accurately, the consumer will probably be in the position to apply filters and projections on the fly by itself. The producer should be in charge of generating new output ports with embedded filters and projections only if it is required for security and compliance reasons because they are accountable.
Rules of thumb
These are the general rules we can apply to the Data Product modelling.
Don’t redistribute the data coming from other Data Products (through output ports) unless you apply a semantic transformation to it. You can redistribute attributes from other Data Products if used in your domain logic or improve the consumer experience.
Pay attention to not creating dimensional modelling in each Data Product. Most of the time, the consumer can retrieve additional attributes from other Data Products, joining them.
Aggregations can be defined at the producer level only if they are working on data that already belongs to the data domain managed by the DP. Don’t create a new data DP to change the data aggregation level. If the aggregation is straightforward, the consumer can handle it; otherwise, if the aggregation is hiding domain logic, it makes sense to keep that within the same data domain the data belongs to.
Denormalized views that facilitate the consumer are allowed and encouraged within the same Data Product as an additional output port. Don’t create a new Data Product to expose the same information (data domain) of another DP with a different format or structure.
Joins should be defined at the consumer level, but only if you are also applying a semantic transformation or a domain-specific business logic. Don’t create a new DP only to join two existing Data Products. There is no business value.
Filters and Projections are defined by the consumer and pushed down in reading operations. Exception: the producer needs to apply them to manage better security and compliance constraints (typically happens on files or events output port where it is not possible to use row filtering and column masking at storage level).
Don’t create new Data Products for technical reasons or performances. If you find yourself doing that, you are probably missing some technological element in your platform. Data Products should follow domain, functional and business drivers, not technical ones.
Final Thoughts
We applied these rules successfully in several enterprise and complex contexts and I hope they will help to elevate the Data Mesh practice.