We Locked a Team in a Room for Two Days and Rebuilt How We Work from Scratch
The Witboost team reimagined software development by locking themselves in a room for two days to create a workflow that challenges traditional processes.
What happens when you throw away your process and start over with AI at the center?
We ran a two-day experiment to answer that question, and the result was clear: when AI is treated as the operating model rather than a coding assistant, delivery speed changes materially without requiring a comparable drop in quality.
What if everything we know about software development is wrong?
In our case, a feature estimated at 30 man-days was brought to a merge-ready state in roughly one working day with four people, producing a 5–6x improvement over our previous AI-assisted workflow. More importantly, the experiment changed how we think about software development itself. The main bottleneck is no longer writing code. It is analysis, context quality, specification clarity, and the discipline required to make AI operate inside a coherent system.
That has practical consequences. Teams that want to work effectively in an AI-native way need to invest first in context, standards, review infrastructure, and documentation. Product and design must stay inside the implementation loop. Developers create the most value in specification, decomposition, testing, and structured context-switching. And the repository must become the single source of truth for both humans and agents.
This is the story of how we reached that conclusion.
The Setup: A Goal Designed to Make Us Uncomfortable
Before we touched a single tool, we started with a provocation. The question we asked ourselves was deliberately extreme: what output would genuinely blow our minds? Not an ambitious but plausible goal — something that, if we achieved it, would force us to update our beliefs about what’s possible.
We landed on this: take a feature estimated at 30 man-days and ship it in one day, with four people. That translates to roughly 4 man-days of elapsed work — a 7.5x compression. We knew going in that four people working in parallel isn’t an efficient setup in the traditional sense. Coordination overhead alone tends to eat 20–30% of the gains. But that was part of the point. We weren’t optimizing for a perfect team structure. We were stress-testing a hypothesis: that the bottleneck in modern software development is no longer writing code, and that if you remove that bottleneck, everything changes.
If we could get anywhere close to that goal, we’d know something fundamental had shifted.
Day One: Building the Machine Before Running It
Here’s what’s important to understand about this experiment: we didn’t just sit down and start coding with AI assistance and call it a new methodology. The first entire day was spent building infrastructure — tools, context, processes — that would make the second day possible. This distinction matters enormously, and it’s one of the things we’d do differently if we were starting from scratch at a new company: invest heavily in the tooling layer before you try to ship anything with it.
Our product is multi-repo, built on a microservices architecture. The first real challenge with AI-assisted development at scale is context. Agents need to understand bounded contexts, respect existing architectural decisions, and navigate a codebase they’ve never fully seen before. Without that foundation, you don’t get AI-native development — you get AI-assisted chaos. Fast-moving, hard-to-reverse chaos.
So we split into several groups and spent the day solving exactly that problem.
Laying the Knowledge Foundation
The first group focused on what we call the constitution — a structured, persistent context that agents inherit before they touch any code or specification. We loaded our existing architectural documentation into it, along with all the pre-existing Architecture Decision Records that capture the reasoning behind the choices we’ve made over the years. Why do we do event-driven communication between these services and not direct API calls? Why do we structure RBAC the way we do? An agent without this memory doesn’t just write suboptimal code — it quietly undermines decisions your team spent months debating. Getting this right felt less like a technical task and more like writing down institutional knowledge that had previously only lived in people’s heads.
Beyond the general architectural constitution, we also created specialized agents designed to provide deeper context on specific implementation patterns. For example, we have a particular way of handling events within the platform — conventions around payload structure, error handling, retry logic — that isn’t documented anywhere formal because it evolved organically. We built an agent that carries that knowledge explicitly, so that when someone is implementing a new feature that generates events, the agent already knows how we do things. The difference in output quality when you give agents this kind of opinionated context is not subtle.
Standardizing the Workflow with SpecKit
A second group spent the day configuring and extending SpecKit as the central spine of our new process. SpecKit lets you standardize the flow from idea to implementation through structured, templated specifications. The template-based extension model was particularly important to us because of something we’ve learned the hard way over the years: We don’t want to be locked into something that doesn't fit our ideas and needs. SpecKit’s template approach means anyone on the team can contribute meaningfully to the specification process — the structure guides them, the templates encode best practices, and no single person becomes a gatekeeper.
Building the Review Infrastructure
Another group built two tools we consider non-negotiable for quality at velocity: an agent-based code review system and an agent-based security review system. The framing here matters. These aren’t replacements for human judgment — good code review and security review require human expertise that agents don’t fully replicate. But they are an extraordinarily effective first pass. By the time a human reviewer sits down with the code, the obvious issues have already surfaced and been addressed. The review conversation starts at a higher level. You spend your cognitive budget on the things that actually require human insight, not on catching the things a machine can catch in seconds.
Solving the Documentation Problem
If there’s one thing that universally suffers when teams move faster, it’s documentation. Speed and documentation quality have historically been in tension. We built a dedicated documentation agent designed to work across the codebase — one agent, one consistent voice, one source of truth for the entire product. The goal was to make documentation not a task that happens after the work is done, but something that emerges naturally from the implementation process itself. In documentation, we adopt the Divio methodology, so the agent needs to understand and stay consistent with it.
The Figma Bridge
One group spent part of the day experimenting with connecting Figma design prototypes directly to our internal React component library through MCP server integration. The hypothesis was straightforward: if the design layer and the implementation layer share a vocabulary — if the same component names mean the same things in both contexts — then the translation work that normally happens between design and engineering largely disappears. We’d find out the next day how well this held up in practice.
End of Day One
At the end of the afternoon, each group presented what they’d built. We assembled the pieces, stress-tested the handoffs, identified a few gaps we hadn’t anticipated, and filled them. What we had at that point wasn’t a product — it was a machine for building one. We went out for dinner with high expectations for the day after.
Day Two: The Day We Shipped the Impossible Feature
We started the morning with a team briefing. Aligned on the goal, clear on roles, and everyone with shared context. Then we opened the Figma prototypes and got to work.
Writing the Spec: Where the Real Work Begins
The first thing we did was begin writing the specification using SpecKit. And here is something important that we did not fully appreciate until we lived through it: spec writing is not a mechanical process, and it shouldn’t be. It is, in fact, the most intellectually demanding part of the entire workflow — and the part where human judgment matters most.
We iterated on the spec several times. Not because the tooling was difficult, but because iterating on a spec is the work. We caught gaps in user stories that seemed complete until we tried to articulate the exact behavior we expected. We surfaced functional holes — entire scenarios we hadn’t thought to address — that would have become bugs or rework if we’d discovered them in implementation. We refined requirements that had seemed clear in the abstract but turned out to be ambiguous when described precisely enough to be implemented.
This friction is exactly what you want. The cost of resolving ambiguity at the spec stage is a few minutes of conversation. The cost of discovering it three days into implementation is several days of rework. The spec phase is where you pay for clarity cheaply.
From the spec, we generated an implementation plan using speckit — a macro-level breakdown of what needed to happen in each software module. We then did an interesting thing: we ran the same exercise independently on a whiteboard, as a team, without looking at what the agent had produced. When we compared the two, the results were strikingly similar. Module boundaries aligned. Sequencing was roughly the same. We adjusted a few things that felt off, iterated for about half an hour, and moved forward with a shared understanding of the architecture we were building toward.
The Task Generation That Changed Our Minds
We then generated implementation tasks for each microservice, and this step produced the single most surprising result of the entire experiment.
We expected structured tasks. We did not expect tasks that demonstrated what felt like genuine architectural reasoning.
The tasks respected API contracts and event payload dependencies between services. They established an implementation order that honored those dependencies — so we wouldn’t end up in a situation where a frontend was waiting on a backend endpoint that hadn’t been built yet. They identified a minimum viable scope: the smallest subset of the feature that would deliver real, demonstrable value to our users. We had trained the agents on our methodology here — we always look for the smallest valuable increment — and they had internalized that principle in a way that showed up concretely in the output.
We reviewed everything carefully. We found errors — some minor, some more significant — and fixed them. The part where it struggled the most has been database design because we realized that our implementation conventions were not strong, but quite fragmented. Total iteration time was about an hour. But what struck us most was what the process forced us to do: going to this level of detail before writing a single line of code makes you confront corner cases you would otherwise stumble on in QA. We found technical debt we hadn’t planned to touch, embedded in the parts of the codebase that the new feature would need to interact with. We integrated addressing that debt directly into the task list, rather than leaving it as a trap for the next person who comes along.
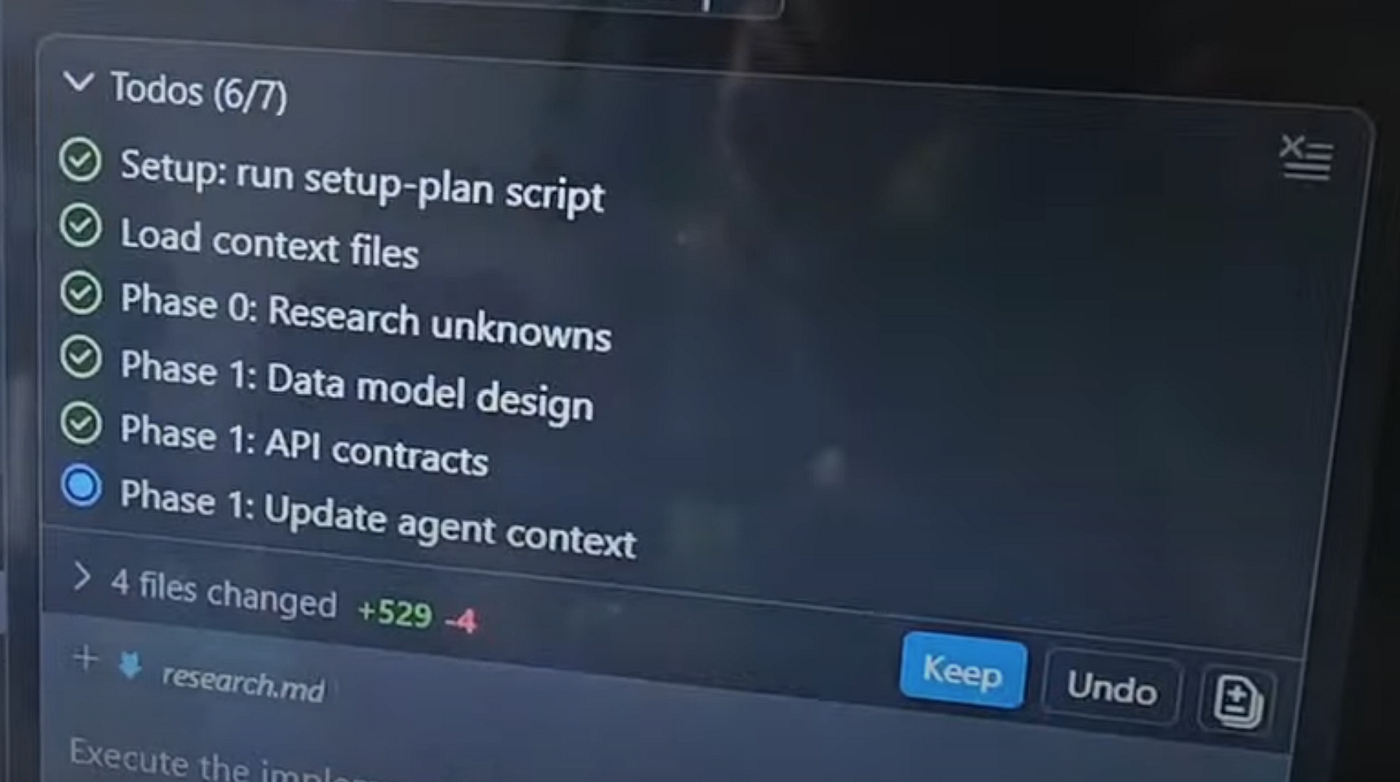
Throughout this phase, we ran SpecKit’s /analyze command repeatedly. It checks for inconsistencies between the spec and the implementation tasks, flags anything that conflicts with the architectural constitution, and surfaces ADR violations before they become code. Each pass tightened the plan. By the time we were done, we had high confidence in what we were about to build and why.
Four People, Four Workstreams, One Goal
With tasks defined and validated, four people launched their implementations simultaneously across different parts of the system.
Frontend moved with remarkable speed. The Figma-to-React bridge held up. Pages came out around 90% correct on the first pass, with interactions behaving as designed. We spent time iterating on smaller things — edge cases in state management, subtle interaction details — but the structural work was done. The time we’d spent the previous day connecting design vocabulary to component vocabulary paid off directly and visibly.
Backend and database were harder, as they always are. Database migrations require precision. Cross-cutting concerns like RBAC don’t compose automatically. There are a dozen things that can go wrong when you’re touching persistent storage in a distributed system, and the agents, to their credit, were aware of most of them — but still needed guidance and iteration. It took roughly two hours to have a first working version of the entire backend surface, which, for a feature of this scope in a mature production codebase, is, frankly, remarkable.
Bringing It Together
Once the individual pieces were working, we shifted into integration mode. The documentation agent produced consistent cross-codebase documentation. Code review surfaced a few issues worth addressing. Security review flagged some minor API concerns — nothing catastrophic, but the kind of thing that in a traditional workflow might have made it to production unnoticed. We addressed everything, ran the full suite, and pushed.
By end of day: the feature was ready to be merged. We actually didn’t because we wanted to take some time to digest it.
The Results: What We Actually Found
Velocity
Compared to our previous workflow — which already incorporated AI through structured prompting, so this isn’t a comparison against a pre-AI baseline — we measured a 5 to 6x improvement in delivery velocity. A feature that would have taken 30 man-days of work arrived in the equivalent of roughly 5 man-days of elapsed time, on a real production codebase with real architectural constraints.
That number deserves some context. We weren’t building a greenfield demo. We were working in an existing multi-repo microservices system with years of accumulated decisions, patterns, and yes, some technical debt. The compression held anyway.
Quality
We audited the output carefully because we expected velocity to come at a quality cost. It mostly didn’t.
The generated code used existing methods and utilities rather than reinventing them. It followed established patterns. When it didn’t, it was almost always traceable to a gap in the context we’d provided — a pattern we hadn’t made explicit in the constitution, a convention that lived in someone’s head rather than in the tooling. This is an important observation: the quality ceiling of AI-native development is largely determined by the quality of the context you build. You get out what you put in, and the investment in day one pays compound interest.
Test coverage was solid. The review agents caught real issues — spec inconsistencies that had survived human review, minor but genuine security concerns. The kind of things that in a traditional workflow would have surfaced later and cost more to fix.
The Human Element
There’s a particular feeling when you’re standing in front of something that, by the logic of your previous experience, shouldn’t have been possible to build in the time it took. The team felt that feeling. Not just satisfaction — something closer to productive disorientation. The ceiling had moved, and we’d watched it move in real time. That’s rare. But at the same time there was a sentiment that we are part of the change and we have a big opportunity to embrace it.
How We’re Changing the Way We Work
Spec Driven Development: All In
At the end of the workshop we decided to adopt Spec Driven Development completely.
Compressing the Analysis Pipeline
Our old process was sequential: Pitch, then High-Level Design, then Low-Level Design, then Implementation. Each phase had its own reviews, approvals, and handoffs. That structure made sense in a world where implementation was slow and expensive — you front-loaded analysis to avoid costly rework.
That tradeoff no longer holds in the same way. Implementation has gotten dramatically cheaper. So we’re collapsing the entire sequence into a single assisted iteration: spec, plan, implement, review, done. The phases don’t disappear — they compress. The time between “we have a clear spec” and “this is live” shrinks from weeks to days or hours.
Product and Design Inside the Implementation Team
This is the most structural organizational change we’re making, and it’s the one that will take the most adjustment. Product managers and designers can no longer hand off requirements and step back. The cost of a wrong spec is too high in this model — a poorly specified feature wastes an entire implementation day and requires starting over from scratch. That’s not a development problem. It’s a product problem. Product and design need to be present during spec iteration, accountable for what’s in the plan, part of the process from the moment the first specification is written.
Parallel Feature Work as a Natural State
While agents elaborate and implement, humans wait. Those waiting periods — which can be minutes or longer, depending on complexity — are not downtime. They’re the natural rhythm of the new workflow, and they create real opportunities: starting the analysis for the next feature, addressing technical debt that’s been sitting on the backlog, reviewing something a colleague is working on. One person can credibly manage two or three parallel workstreams. The cognitive cost is real — context-switching at depth requires a particular kind of concentration — but the throughput gains are substantial.
Pure Streaming Delivery
The product manager prioritizes the backlog. The team pulls features and implements them continuously. We’re moving away from the overhead of complex sprint ceremonies around sequencing and toward a simpler model: clear priorities, a reliable process, and a team that knows how to execute. Work flows in, product flows out.
Release Cadence Stays
Despite everything else changing, we’re keeping our 8-week release cycle with a 2-week consolidation freeze. Velocity of implementation doesn’t mean you skip the work of making software reliable and integrated. If anything, you arrive at the freeze period with more to integrate — which is a good problem to have, but still a real one.
What It Means to Be a Top-Performing Developer in This New World
This is perhaps the most important section of this entire piece, because it’s the one that touches the people doing the work.
The image of the elite developer — headphones on, deep in flow, crafting elegant code for hours at a stretch — is changing. Not disappearing, but transforming into something that looks quite different. Here’s what we think top performance looks like in an AI-native team.
80% of Your Focus Goes to Analysis
The single most valuable thing a skilled developer can do in this model is think deeply about the problem before any implementation begins. High-level design and low-level design are no longer upstream activities that someone else handles and then hands over — they are the core of the craft.
This means the analysis phase becomes the new moment of flow. The phase that demands headphones on, no Slack, no interruptions, full cognitive presence. Not because it’s hard in a mechanical sense, but because the quality of everything that follows depends entirely on the quality of thinking that happens here. A spec written with half your attention produces a feature built with a significant fraction of wasted effort. A spec written with full focus, genuine architectural clarity, and rigorous attention to corner cases produces a feature that arrives clean and complete.
Senior developers will be distinguished not by how fast they can write code, but by how accurately they can model a problem, decompose it into coherent modules, anticipate the edge cases, and produce a plan so clear that an agent can execute it faithfully. That is a very high bar, and it’s a different bar than most teams have been measuring against.
Context Switching as a Core Skill
As implementation runs, developers have natural pauses in their active attention requirements. The developers who thrive in this model are the ones who use those pauses deliberately — pulling in the analysis of the next feature, addressing a piece of debt that’s been deprioritized, reviewing a colleague’s spec. Two or three parallel workstreams become manageable and even natural.
But here’s the important nuance: this is not the mindless multitasking of someone toggling between Slack and a text editor. This is deliberate, structured context-switching between well-defined work items, each with its own clear state. Managing that requires the same discipline as deep work — just applied to a different kind of attention. Developers who can do this well will have outsized impact. Developers who can’t will find the waiting periods frustrating rather than productive.
20% of Your Focus Goes to Testing
When you haven’t written every line of code yourself, your relationship to testing changes fundamentally. You can’t rely on the implicit knowledge that comes from having built something by hand — the sense of where the fragile bits are, what you cut corners on, which edge case you quietly decided not to handle. You have to test as if you’re encountering the code for the first time, because in a meaningful sense, you are.
This means testing all the corner cases. The ones that feel unlikely. The ones that require setting up awkward state. The ones that cross service boundaries in ways that are hard to simulate. Testing isn’t a phase that happens after development anymore — it’s woven into the task structure from the beginning, and the final validation of the artifact needs to be thorough and systematic. The quality of what you release is directly proportional to the quality of your testing, and there’s no longer a fallback of “well, I wrote this code, so I know what it does.”
Communication and Transparency as Professional Obligations
This one is subtle but important, and we think it will define a lot of team dynamics over the next few years.
As AI handles an increasing fraction of the mechanical work of software development, there’s a predictable risk of a certain kind of managerial anxiety: what are people actually doing while the machine is running? The question is fair. In a world where the assumption — sometimes stated, more often implied — is that AI does 80% of the work, it becomes very easy for people in leadership positions to wonder whether their teams are genuinely pushing for maximum velocity or whether they’re waiting passively for the agent to finish before moving on to the next task.
This anxiety, left unaddressed, corrodes trust. And trust is what high-performing teams run on.
The response to this isn’t to work harder or to prove business through performative activity. It’s to build new habits of communication and transparency that make the work visible in ways that matter. Not status updates for the sake of status updates, but genuine, substantive signals of how the team is thinking about velocity, quality, and opportunity. What are we doing with the waiting time? What did we analyze today that we’ll implement tomorrow? What technical debt did we surface and address? What did we learn that will make the next feature faster?
This becomes a new kind of professional contract — not just between developers and their managers, but between the entire team and the organization. In an AI-native world, the measure of a top developer isn’t lines of code written or tickets closed. It’s the quality of the thinking they apply to hard problems, the velocity they enable through rigorous analysis, and the trust they build through radical transparency about how they spend their attention.
The developers who understand this and act on it will be the ones who thrive. The ones who don’t will find themselves in an increasingly uncomfortable position, regardless of how technically talented they are.
The developer wait
The Philosophy: The Repository as the Single Source of Truth
Underneath everything we’ve described — the tools, the agents, the compressed timelines — there is a single organizing principle that holds it all together. It’s simple enough to state in one sentence, but it has implications that touch every part of how the team works:
Everything lives in the repository. Everything.
Not some things. Not the things that are convenient to put there. Everything. Architectural documentation. High-level design. Low-level design. User stories. Specs. Bug reports. Implementation decisions. ADRs. All of it, expressed in Markdown, committed alongside the code it describes.
This sounds like a workflow preference. It’s actually a philosophical stance.
Why This Matters
In most teams — including ours, until recently — knowledge is scattered across tools that don’t talk to each other. The high-level design lives in a PowerPoint deck somewhere in a shared drive. The architecture diagrams are in draw.io, or Miro, or on a whiteboard that someone photographed and uploaded to Confluence. The user stories and task breakdowns live in Jira. The implementation decisions are in someone’s head, or in a Slack thread from eight months ago that nobody can find.
Each of these tools is perfectly functional in isolation. The problem is that they create a fragmented picture of reality — one where the connection between a business requirement and the code that implements it is invisible, implicit, or simply lost over time. When a new developer joins and asks why does this service work this way, the honest answer is often I’m not sure, it was before my time.
This fragmentation is a problem in any development context. In an AI-native context, it’s a critical failure point. Agents can only reason about what they can see. If your architectural decisions live in PowerPoint and your user stories live in Jira, your agents are working blind — generating code that is locally coherent but globally adrift. You end up with fast execution on top of shallow understanding, which is a combination that produces technical debt at speed.
The Repository as a Living Knowledge Base
The shift we’re making is to treat the repository not just as a place where code lives, but as the single place where everything about the product lives. Every spec is a Markdown file. Every user story is a Markdown file. Every architectural decision, every known bug, every implementation plan — all of it committed, versioned, and co-located with the code it describes.
The immediate practical consequence is that GitHub Copilot — and any other agent operating on the codebase — can index all of it. When an agent is implementing a new feature, it doesn’t just see the code. It sees the spec that drove the feature, the ADRs that constrained the design choices, the user stories from adjacent features, the bug reports that reveal where the system has been fragile in the past. It has the full context of the product’s history and intent, not just its current state.
This changes the quality of what agents produce in a way that compounds over time. Every spec added to the repository makes the next spec easier to write and more consistent. Every ADR recorded makes future architectural decisions more coherent. Every user story committed gives the agent more signal about how the team thinks about the product and its users. The knowledge base doesn’t just accumulate — it becomes increasingly coherent, because it all lives in one place and is all visible at once.
The Discipline It Requires
We want to be honest about something: this approach requires discipline that doesn’t come for free. It’s tempting to open PowerPoint for a quick architecture sketch, or to throw a few tasks into Jira because that’s where the project manager is looking, or to have a design conversation in Slack and never write it down. These habits are deeply ingrained, and they’re ingrained for good reasons — those tools are fast and familiar.
But every time knowledge escapes the repository, it becomes invisible to the agents and to the team members who weren’t in the room. The value of the single-source-of-truth approach is entirely dependent on the consistency with which it’s maintained. One PowerPoint that contains a critical architectural decision is a leak in the system. One Jira ticket that captures a design choice nobody transferred to Markdown is institutional knowledge that is one tool migration away from disappearing forever.
The upside is that Markdown in a repository is the most durable, most portable, most tool-agnostic format that exists. It doesn’t depend on a vendor. It doesn’t require a license. It renders everywhere. It diffs cleanly. And it will be readable — and indexable by whatever agents come next — for as long as text files exist.
We think that’s a trade worth making.
On Team Structure: This Is Not About Doing More With Less
During the workshop, the team itself raised the question that’s probably on everyone’s mind when they see numbers like 5–6x velocity improvement: does this mean we need fewer people? We also joked a lot on this topic !!
It’s a fair question, and we want to answer it directly.
No. That’s not what we’re doing, and we don’t think it’s the right frame.
This is not an opportunity to reduce headcount and maintain current velocity. It’s an opportunity to keep the team and dramatically increase what the team can accomplish. Those are very different strategies, and in our view, only one of them makes sense right now.
Here’s the underlying belief: in the world we’re entering, speed is everything. The defensibility of a software business is no longer primarily a function of how much code has been written over the years, how deep the technical moat is, or how long it would take a competitor to replicate the surface area of the product. Those things matter less than they used to. What matters more — increasingly more — is the speed at which a team can move in a clear direction. How fast you can learn, validate, build, and ship. How quickly you can respond when the market moves or a competitor appears.
Given that, the question isn’t how do we use AI to do the same things with fewer people? The question is how do we use AI to do things we couldn’t previously have done at all? Features that were too expensive to justify. Improvements that kept getting deprioritized. Entirely new directions that felt out of reach given the team’s bandwidth.
The temptation to optimize for cost savings when you discover a productivity multiplier is understandable — it produces an immediate, legible return. But it’s optimizing for the wrong thing. You’d be trading a compounding velocity advantage for a one-time reduction in the salary line. In a market where speed is the primary source of defensibility, that’s a bad trade.
Our intention is the opposite: invest the productivity gains back into acceleration. More ambitious roadmaps. Faster iteration cycles. The ability to pursue opportunities that previously required a business case we couldn’t make. This is the moment to push forward harder, not to consolidate.
A Final Thought
We didn’t just build a feature faster over those two days. We found a different shape for how a software team can operate — one where the bottleneck has moved, the value distribution has shifted, and the skills that matter most have changed in ways that aren’t always obvious.
The old model assumed a certain ratio between thinking and building, between senior and junior contribution, between product and engineering. Those ratios have shifted discontinuously, not gradually. And the teams that adapt their processes — and their culture, and their measures of performance — to reflect that new reality will have a compounding advantage over the ones that don’t.
We’re not done figuring this out. We built a machine in two days and ran one experiment. There are a hundred things we’ll tune, a dozen things we’ll discover are harder than we thought, and probably a few things we’ll find out we got completely wrong. But we know enough now to be certain of one thing: the ceiling moved. And we’re not going back to the room we were in before we saw that.
Have you run a similar experiment with your team? What did you find? We’d love to compare notes.