Data Contracts
How Witboost Maximizes Data Contracts
Discover the potential of data contracts in Witboost and how they enhance data quality, governance, and interoperability.
Discover the role of Data Mesh Observability in decentralized data ecosystems. Explore its conceptual aspects that can enhance data product quality.
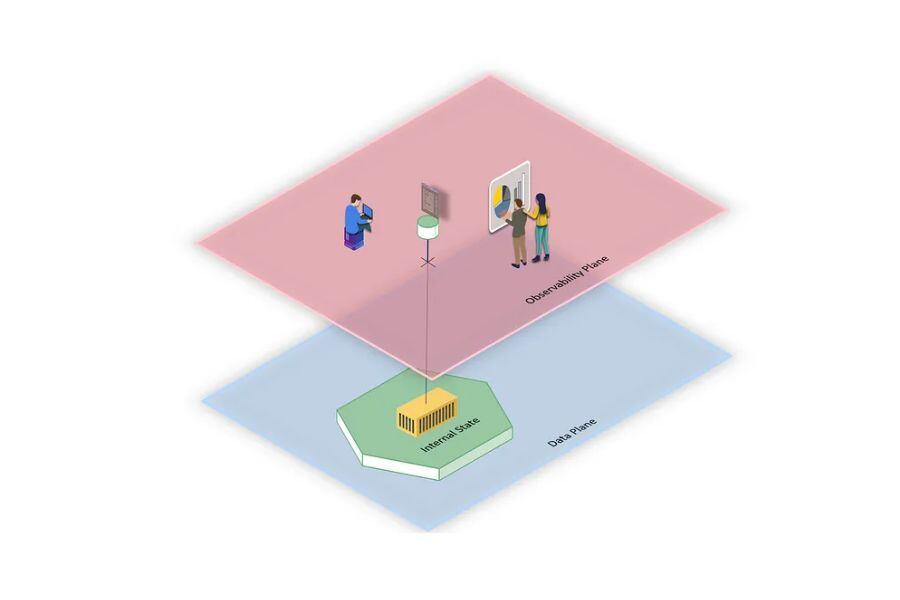
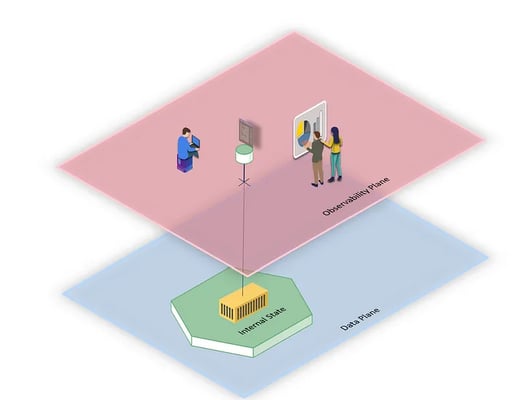
In this article, we delve deeper into the concept of Data Mesh Observability and see how this is of fundamental importance also for many other aspects within Data Mesh architectures.
Within the decentralized paradigm of Data Mesh, trust among various actors is a fundamental element of the paradigm itself. Conveying transparency and trust to all data consumers is exactly why a concept of observability for each data product has been coined.
In the original storytelling, the concept of observability remains very abstract and high-level. That's why we aim to be specific on this topic with two articles.
In this first article, we will discuss the conceptual/theoretical part, covering the role of observability and its characteristics. In the second part, we will delve into the architectural/implementation aspects.
At a high level, observability allows an external observer to understand the internal state of a data product, which by design should not be exposed (except for the external interfaces set up, such as output ports, etc.).
In fact, observability is one of the exposed and standardized interfaces that allow interaction with a data product without having to deal with its internal complexities.
First, let’s explore in which contexts observability plays a role and brings value within a Data Mesh ecosystem.
Put simply, we must make the data product observable. - Paolo Platter
Data products expose data through output ports, which are effectively data contracts defined by the data producer that represent a promise on how data will be provided to data consumers.
These promises typically cover 4 areas:
1) Technical information, such as schema and data types.
2) Semantic information, like business information and meaning.
These two can be defined as static information, i.e. they don't change every time the data changes (unless there are breaking changes).
3) SLAs
4) Data quality
These latter two are dynamic information, i.e. they need to be continuously verified (even when the data doesn't change).
If we want a data consumer to trust what we offer, we must provide them with visibility and transparency. Put simply, we must make the data product observable. It is not enough to provide the current state of the system, we must also demonstrate that our data product has a good track record of reliability (few data issues, low mean time to recover, etc.).
The Data Mesh professes an ecosystem where all data products are independent in terms of change management, but this independence is not so obvious in terms of business processes, which are often strongly interconnected. Let's take a look at an example:
Imagine having Data Product A and Data Product B. At the process level, Data Product B needs the updated data from Data Product A to perform its function. In this case, Data Product B must observe what happens in Data Product A, understand when data is refreshed, understand when its scheduling chain is actually finished to not consider partial refreshes, and must understand if it is in good shape before consuming the data.
These pieces of information are significantly different from the previous ones and must necessarily be machine-readable to allow Data Product B to make autonomous and real-time decisions on how to proceed with its orchestration. So even here we're talking about making the internal state of the data product observable. If before it was exclusively related to the data state, now it is more related to the internal process state.
Audit and compliance functions perform a cross-cutting and strongly centralized activity. They are usually interested in receiving information about when, how, and who performed certain operations.
For concrete examples, they want to know how and when a deployment was executed, who deleted data, who restarted the scheduling of a data product, etc. In short, every operation (automatic and manual) that is carried out on a data product is subject to audit.
One way to democratize this information is to standardize this set of necessary information, making it mandatory in the data product implementation cycle, and finally make this information accessible and observable.
These are also part of the concept of observability, as they allow third parties to know something that happened or is happening inside the data product, standardizing the communication interface.
The function that deals with analyzing a company’s business processes (process mining) needs to understand the timing of the various phases of each business process.
When a business process is directly implemented within data processing pipelines or data transformations, it becomes crucial to be able to observe the various processing steps, the timestamps with which they were executed, and also the processing times of the individual informational unit (such as the processing of a payment, a customer profile, etc.).
A Data Mesh observability pattern can standardize this type of information and make it usable so that it is possible to perform process mining calculations through processing chains that span several data products.
Being able to view what happens inside the data product is also very useful for Data Product Teams. This is because, as data products are often created and delivered by a self-service layer, it might become difficult for the data product team to understand where the jobs are actually executed, what the URLs are for monitoring them, and where we are in the scheduling chain.
This information is vital for observing the behavior of a data product, troubleshooting, and then intervening with operations (through control ports) to fix various problems.
If a company wanted to embark on a path of adopting the FinOps practice (remember, it is a practice), one of the first steps would be to establish a mechanism for showback or chargeback of costs for each team.
The goal of this operation is twofold: to increase Data Product Teams' awareness of resource use, and then to give visibility on it to the FinOps team. This way they can carry out impact analyses, suggestions, and evolutions of the FinOps platform.
In this case, we are talking about making “internal” information about the data product (i.e. billing) available to the outside world. We are making it observable. Another important case is when during Data Mesh implementation it's decided that part of the costs of a data product are charged to consumers. It then becomes essential to demonstrate that the amounts charged to consumers are derived from real costs.
The observability structure within Data Mesh architectures must be designed with the below characteristics in mind. We will delve into the conceptual aspects, while in part 2 of this blog, we will see concrete data mesh implementation examples.
All the use cases explained above are not priority zero, so they will be implemented as Data Mesh takes hold within the organization and enables data product thinking. Even a single functionality can start with a simple MVP (minimum viable product) and then evolve and become more complex over time.
However, this doesn't mean that the architectural mechanism being used for observability doesn't need to anticipate this evolution from the outset. It absolutely must.
My advice is to use a mechanism based on REST APIs to implement observability so that it enables API versioning, and makes it possible to structure the paths in a way that allows new features to be added along the way. Even at the API contract level, i.e. the content that will be exposed, it must be designed so that it's extensible over time.
I recommend designing your standard for data exposure within observability and not adopting the APIs of any platform or tool, as this will become a technology lock-in in the long run and will not guarantee the necessary evolvability.
The observability metrics exposed by a data product must allow the current state of the system to be understood but also provide historical evidence that the data product is reliable and reliable. These two aspects must be part of the standardization of the contract.
It’s important that observability information is the result of a structured and standardized process. It must be non-tamperable and not modifiable post-facto by the data product owners or other entities. In this aspect, a data observability platform plays a fundamental role.
If the observability mechanism becomes an integral part of the value chain that is established between the various data products, it must be very reliable. If poorly designed, it could become a single point of failure with mission-critical impacts for the entire ecosystem.
Therefore, it is crucial to create a data observability platform that provides the right trade-off between centralization/decentralization (we will delve deeper into this topic in part 2) and operational independence of the individual data products.
This detailed exploration underscores the critical importance of data mesh observability within the paradigm. Observability not only fosters trust and transparency among the various actors involved but also enhances the overall functionality and efficiency of the data ecosystem.
By integrating a data mesh observability pattern, organizations can effectively manage and monitor their data product quality metrics, ensuring data reliability, compliance, and operational excellence. The concept goes beyond mere visibility, embedding a systematic approach that is essential for modern data architectures and strategies.
Discover the potential of data contracts in Witboost and how they enhance data quality, governance, and interoperability.
Data Mesh is completely changing the perspective on how we look at data inside a company. Read what is Data Mesh and how it works.
Explore four data contract implementation patterns for complex environments, emphasizing proactive measures to prevent data issues and maximize...